Stop Expecting Certainty from Probability Machines

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Authored On
Modified
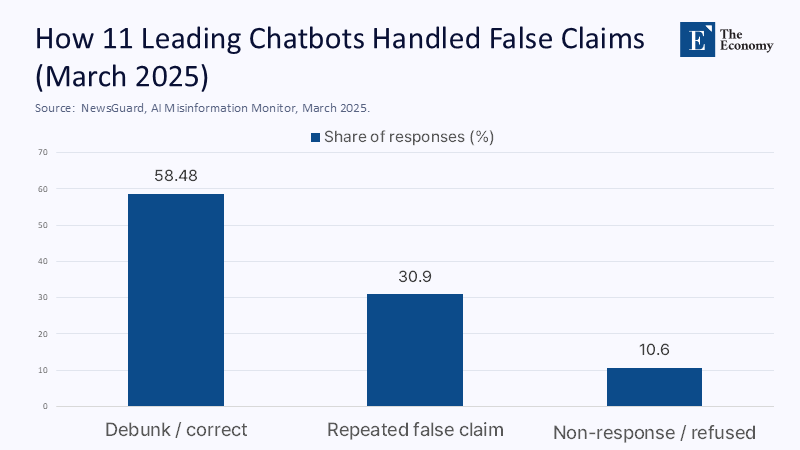
In March 2025, an independent audit of 11 leading chatbots found that when confronted with news-related prompts, these systems either repeated false claims or dodged the question in more than 41% of cases; in barely three-fifths of responses did they deliver a competent debunk. Performance has plateaued across months despite expanded web access and retrieval tricks, suggesting a ceiling on short‑term progress. The explanation is not mysterious: these models are engineered to predict likely words, not to reason about what is true, and so they excel at plausible prose while remaining structurally indifferent to accuracy. In practical terms, this means the most polished answer can still be the wrong one—and often is when the information is hot, contested, or obscure. Treat a probability engine like an authority, and you will inherit its confabulations. Treat it like a stylist, and you will get its best. The policy consequence is immediate: we should curb reliance, not the technology.

Reframing the Problem: From Model Capability to Human Reliance
The public debate often revolves around a mirage: the belief that with enough computing power and tuning, general chatbots will become reliable authorities for high‑stakes facts. This assumption misinterprets the purpose of the systems in question. Large language models (LLMs) aim to minimize next‑token error, a goal that results in fluent and adaptive text but does not guarantee fidelity to reality. Even as researchers debate the degree of emergent reasoning these systems display, the observed changes in behavior over time—significant fluctuations in accuracy across months—underscore why authority status is misplaced. When outputs vary with training cycles, data mixtures, and reinforcement regimes, the prudent policy stance is to design for fallible output and human verification. The reframed question is not “How do we make LLMs infallible?” but “How do we constrain where we trust them?” This shift in perspective is crucial because these systems have been integrated into search, office software, and classrooms faster than institutional guardrails have matured.
What the 2024–2025 Numbers Say
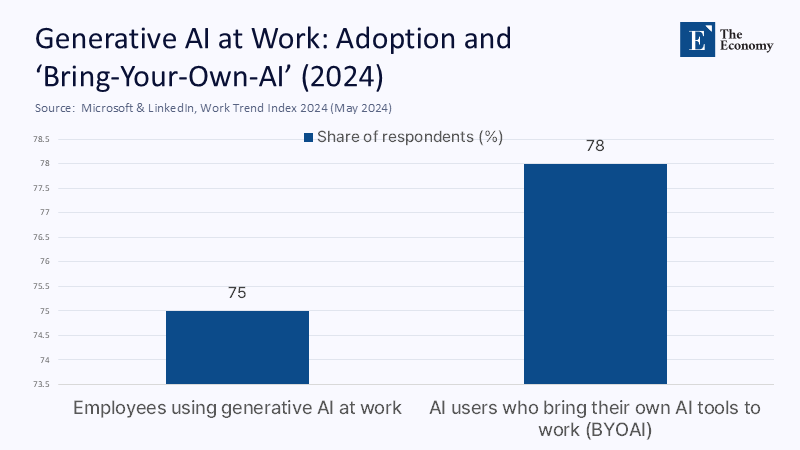
Across knowledge work, adoption is real and rising: by May 2024, Microsoft’s global survey reported 75% of knowledge workers using generative AI at work, often without formal guidance. Yet adoption has not translated into dependability. NewsGuard’s monthly monitors record that leading chatbots still repeat provably false narratives roughly one‑third of the time—and, taken with non‑answers, fail in about 41% of prompts. Meanwhile, public skepticism is durable: Pew’s April 2025 study found majorities of both adults and AI experts more worried that the government will regulate too little rather than too much. In journalism, the Associated Press permits experiment‑only uses with mandatory human vetting; core news gathering remains human‑led. The EU’s AI Act is converging on transparency over trust, requiring disclosure for AI‑generated content and summaries of training data. Together, these data points show a market already adjusting its behavior: heavy use paired with institutionalized doubt.
A Market Correction Is Already Underway
Users are not passively waiting for regulators to rescue them; they are adapting their habits. In search, Google’s AI Overviews drew widespread criticism after surfacing confidently wrong advice—from “glue on pizza” to “eat rocks”—prompting the company to deploy targeted fixes and public defenses. News publishers, seeing traffic diverted to AI summaries, have escalated complaints and retooled distribution. In courts and professional services, early case law is clarifying that hallucinated outputs are not automatically actionable against vendors, primarily where disclaimers and independent verification exist; the Walters v. OpenAI decision in Georgia placed weight on context and user responsibility. These pressures are classic market signals: when convenience collides with reputational or legal risk, organizations re‑interpose human review, narrow use cases, and rely on institutional brands that can be held to account. The more brilliant strategy is to codify that emergent discipline rather than fantasize about a near‑term omniscient machine.
Policy That Matches the Physics: Tiered Reliance, Not Blank‑Check Trust
Risk‑based governance is most effective when it targets reliance instead of raw capability. The EU’s AI Act already pushes in this direction: transparency labels and special obligations for high-impact general-purpose systems, with stricter rules in high-risk domains like education and employment. The US NIST AI Risk Management Framework likewise encourages organizations to operationalize risk identification, measurement, and mitigation without freezing innovation. For schools and media, the most effective complement is provenance infrastructure—notably C2PA Content Credentials—so institutions can signal what was human‑created, what was AI‑assisted, and what sources underlie any claim. This is a market lever: over time, audiences and advertisers reward outlets with verifiable trails and demote unattributed syntheses. Rather than pre‑clear every model or micromanage architectures, policy should set reliance thresholds by context and require auditable disclosure when AI touches claims of fact, reserving heavier liability for repeat misrepresentation in regulated, high‑stakes settings.
What This Means for Classrooms and Campuses
So, what does all this mean for classrooms and campuses? Educators should declare large language models (LLMs) out of scope for authoritative facts, while embracing them as powerful language instruments. This is not just a rhetorical line; it should structure the workflow. In research methods courses, for instance, students should be required to source claims from primary literature, with the model limited to stylistic tightening and outline generation. In writing centers, AI can be used for tone, organization, and grammar, but should be quarantined from citation generation or factual assertions. Administrators can adopt newsroom‑style rules: every AI‑touched assignment should include a short 'provenance note' (tools used, prompts, and human checks performed), and any factual statement must be grounded in verifiable sources. For communications, content credentials can be adopted on institutional sites to flag AI‑assisted materials. Finally, procurement should be updated to mirror NIST’s risk guidance—vendor attestations of retrieval sources and logging, default citation features, and toggles that turn off generative answering in 'your money or your life' categories. The bottom line is clear: use AI to polish language, not to authenticate reality.
Anticipating the Obvious Objections—and Answering Them
Objection: “As models improve, hallucinations will vanish; it’s premature to constrain reliance.” Evidence cuts the other way. Across months of audits, failure rates have stagnated despite web access, and independent studies continue to document hallucinations even in domain‑tuned legal tools marketed as “hallucination‑free,” with rates ranging from the high teens to roughly a third. Retrieval‑augmented generation helps but does not eliminate the problem; recent surveys and clinical evaluations show mitigation in narrow settings, not general immunity. Objection: “Heavy regulation is the only answer.” Overbreadth risks locking in incumbents and missing the fast‑moving edge of product design, while market norms—from AP’s rules to newsroom provenance labels—are already narrowing irresponsible uses. Objection: “We can trust AI more than humans.” Trust attaches to institutions that stand behind claims, not to architectures. When publishers misstate facts, we know where to complain. With general chatbots, we do not. That asymmetry is why reliability must ride on brand, not on bots.
Implementation Playbook for Policymakers, Editors, and Educators
The near‑term path is pragmatic. First, legislate and adopt truth‑in‑provenance: require standardized AI‑content disclosures for public agencies and publicly funded schools, and encourage private adoption through procurement preferences. Second, set reliance boundaries by domain: in health, finance, law, and K‑12 assessment, generative systems may assist style and structure. Still, they cannot be the final arbiter of facts absent independent sources. Third, mandate citation defaults for any system that summarizes or answers questions—no citations, no claim—and retain logs for audit. Fourth, invest in verification capacity: librarians and copy desks are not dead weight; they are the safety layer. Fifth, create a liability ladder: users and publishers who ignore provenance signals or remove labels shoulder more risk; core model providers face targeted duties to prevent illegal content and to publish data‑use summaries, as the EU now requires. This is not anti‑innovation; it is market hygiene for an era when fluency is cheap and accuracy is scarce.
Keep the Pen; Lease the Polish
The most critical number in this debate remains the 41% failure footprint recorded across leading chatbots on news prompts. It is not a scandal; it is a specification. Probability machines produce plausible language, not verified truth. The public has already intuited this, which is why adoption rises even as trust plateaus and policies in newsrooms, campuses, and court systems shift toward disclosure and verification. The task now is to align governance with reality: treat general chatbots as workflow accelerators and tone adjusters, cap their authority in high‑risk contexts, and build provenance rails that return credit and liability to institutions with names on the door. If we do that—codifying reliance boundaries, not fantasy guarantees—students will learn to write more clearly, editors will publish with fewer errors, and policymakers will preserve the market’s ability to improve tools without outsourcing judgment to them. Keep the pen; lease the polish. That’s the bargain worth making.
The Economy Research Editorial
The Economy Research Editorial is located in the Gordon School of Business and Artificial Intelligence, Swiss Institute of Artificial Intelligence.
References
Associated Press. (2023). Standards around generative AI. Retrieved July 30, 2025.
Associated Press. (2024). Updates to generative AI standards. Retrieved July 30, 2025.
CourtListener. (2023–2025). Walters v. OpenAI, L.L.C., 1:23‑cv‑03122. Retrieved July 30, 2025.
Edelman. (2024). 2024 Edelman Trust Barometer. Retrieved July 30, 2025.
European Parliament. (2025). EU AI Act: First regulation on artificial intelligence (updated February 19, 2025). Retrieved July 30, 2025.
Ji, Z., Lee, N., Frieske, R., et al. (2022). Survey of hallucination in natural language generation. ACM Computing Surveys.
Manakul, P., Liusie, A., & Gales, M. (2023). SelfCheckGPT: Zero‑resource black‑box hallucination detection for generative LLMs. arXiv.
Microsoft WorkLab & LinkedIn. (2024). AI at work is here. Now comes the hard part (Work Trend Index). Retrieved July 30, 2025.
NIST. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). Retrieved July 30, 2025.
NewsGuard. (2025, April 8). March 2025—AI Misinformation Monitor of leading AI chatbots. Retrieved July 30, 2025.
Pew Research Center. (2025, April 3). How the U.S. public and AI experts view artificial intelligence. Retrieved July 30, 2025.
Reuters. (2025, May 19). OpenAI defeats radio host’s lawsuit over allegations invented by ChatGPT. Retrieved July 30, 2025.
Search Engine Land. (2024, May 28). Google AI Overviews under fire for giving dangerous and wrong answers. Retrieved July 30, 2025.
Stanford Center for Research on Foundation Models. (2024). Foundation Model Transparency Index (v1.1). Retrieved July 30, 2025.
Sonnenfeld, J. A., & Lipman, J. (2025). AI is getting smarter—and less reliable. Yale Insights. Retrieved July 30, 2025.
Wagner, A., et al. (2023). How is ChatGPT’s behavior changing over time? Harvard Data Science Review. Retrieved July 30, 2025.
Content Authenticity Initiative & C2PA. (2025). Reflecting on the 2025 Content Authenticity Summit at Cornell Tech. Retrieved July 30, 2025.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.