When Intelligence Pollutes: The Climate Cost of Our AI Future

Input
Modified
When ChatGPT's blue reply light blinks, the planet's electricity meter begins to sprint. That small but telling synchrony captures the hard pivot in humanity's digital story: a decade ago, we lauded the "cloud" as a weightless substitute for carbon-heavy travel and paper; in 2025, we discovered that the computational clouds cast a widening carbon shadow. Unless we turn the engines of artificial intelligence (AI) into relentless misers of joules, decarbonization promises will evaporate in a plume of GPU exhaust. The good news is that efficiency gains are technologically feasible and politically actionable; the bad news is that wishing for them is no longer enough.

The Mirage of Digital Frugality
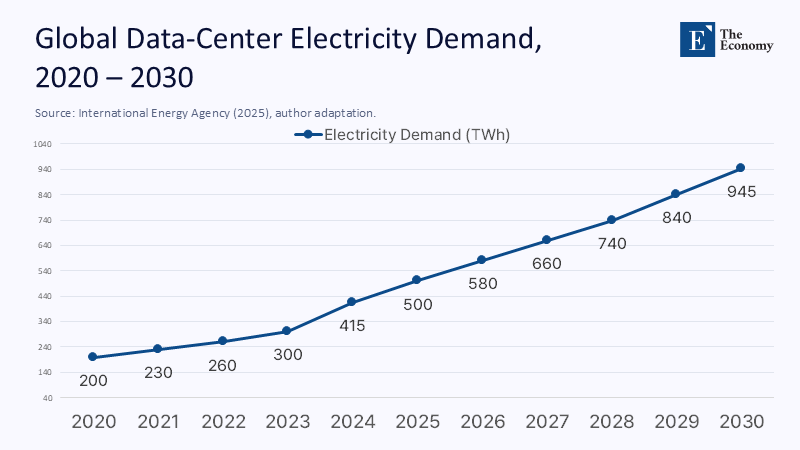
Early‐century forecasts claimed that moving meetings, classrooms, and archives online would slash energy demand. Yet global data-center electricity use still climbed to roughly 415 TWh in 2024—about the annual demand of Saudi Arabia—before any mass roll-out of generative AI had fully hit the grid. Instead of leveling off, the curve steepened: by early 2025, the International Energy Agency projected that data-center demand could pass 945 TWh by 2030, overtaking Japan's current consumption. In other words, the virtual migration doubled back into the physical world, requisitioning gigawatts of fossil-reliant capacity that policymakers had earmarked for electrifying transport and heating. The "paper saved" narrative disguised a deeper dynamic—the physics of information itself. Every inference, search query, or zoomed lecture releases heat as surely as a gas boiler; the cloud is a factory in disguise.
GPU Mania and the New Carbon Curve
The driving force behind this surge is the graphics processor unit, particularly Nvidia's H100 and its successors. Each H100 card can draw up to 700 watts; an eight-card DGX node exceeds 5.6 kW before considering cooling or networking overhead. A hyper-scale cluster of 100,000 H100s consumes around 150 MW of IT power—roughly half the output of a midsize nuclear reactor—once switches, storage, and CPUs are factored in. If we multiply this by the number of frontier labs, it becomes clear that AI alone could surpass the electricity footprint of entire medium-sized countries. Scientific American predicts that, if current trends continue, total data-center demand could double in five years, with generative models being the primary driver. This is a stark reminder of the potential environmental impact of AI's energy consumption.
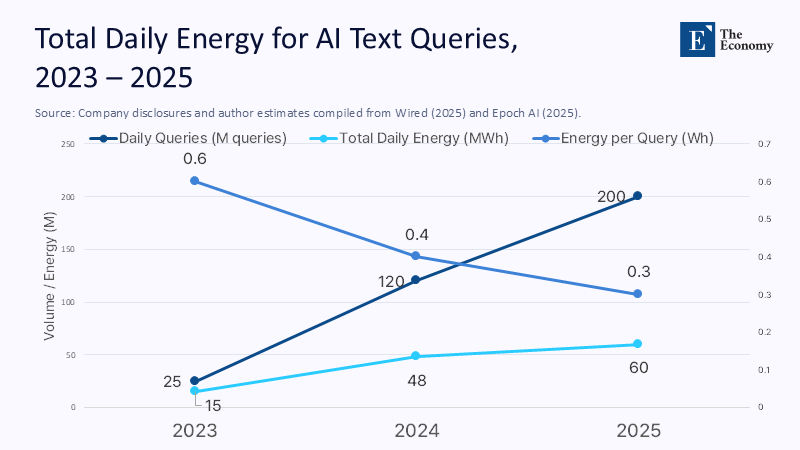
The macro-scale curve is mirrored in micro-scale metrics. A 2025 Wired investigation notes that corporate secrecy still clouds exact figures, but available estimates place a typical ChatGPT query at roughly 0.34 Wh. The open-source group Epoch AI arrives at a similar 0.3 Wh per "interaction" for GPT-4o. Though that may seem paltry—about the energy needed to light an LED for an hour—multiply by two hundred million daily requests, and one obtains 60 MWh per day or the daily consumption of 5,000 European homes. Such arithmetic should sober the education sector, which increasingly embeds conversational AI in every learning management system and homework app.
Thermodynamics of Thought: Quantifying AI's Appetite
A fuller energy ledger must add training costs. Peer-reviewed estimates suggest GPT-3 burned through about 1,287 MWh during its 2020 training run, while the open-access BLOOM model needed 433 MWh. GPT-4, trained on exponentially more data and parameters, has been modeled at between 7,100 and 15,000 tCO₂e—twelve times GPT-3—depending on assumed power-usage effectiveness and grid mix. Although the one-off training phase is amortized over billions of inferences, it remains a carbon lump sum that has to be repaid by sizeable efficiency gains downstream if net reductions are to materialize.
What, then, is the theoretical floor? Shannon's information limit tells us the minimal joules per bit, but practical systems idly waste orders of magnitude more. Even modest algorithmic tweaks can cut floating-point operations (FLOPs) by half, yielding immediate kilowatt relief if matched by proportional hardware utilization. Unfortunately, current market incentives reward peak capability, not frugal execution. The carbon trajectory, therefore, hinges on whether efficient R&D can outrun demand elasticity.
Why Scale Alone No Longer Guarantees Better Answers
For policy debates, raw watt-hours matter less than marginal utility per joule. Evidence is mounting that model accuracy saturates beyond a threshold of model size when applied to tasks that are too tightly scoped, especially in K-12 and higher education, where curricula are domain-constrained. Studies comparing specialized 7-billion-parameter instruction-tuned models against exotic 70-billion giants often find trivial quality gaps in essay grading or adaptive quiz generation. Yet, the computed delta is a whole order of magnitude. That means institutions frequently pay for imperceptible quality gains in electricity and cash. Worse, the rebound effect ensures that once a more capable model exists, platforms will find new bells and whistles—full-resolution multimodal generation, real-time voice avatars—that quickly erase any energy savings derived from parameter-pruning alone.
From Megaflops to Millijoules: The Emerging Toolkit for Lean Models
Still, promising technical pathways can break the spiral. Sparse Mixture-of-Experts (SMoE) routing activates only a small subset of parameters at inference time; fresh arXiv work in 2025 shows that SMoE models can match dense counterparts on massive text-embedding benchmarks while cutting FLOPs by 80%. TT-LoRA and related techniques combine low-rank adaptation with sparse expert selection, yielding four-fold reductions in training FLOPs when fine-tuning domain models. A complementary line—"drop-upcycling"—re-initializes only strategically chosen blocks of a pre-trained dense network, achieving parity with models twice its active size at one-quarter the energy cost.
Meanwhile, hardware co-design pushes the efficiency frontier outward. Prototype photonic tensor cores promise >10 TOPS/W, an order of magnitude leap over today's CMOS GPUs, while analog-in-memory accelerators eliminate data-movement energy for matrix multiplies. Yet unless such breakthroughs diffuse faster than demand, their carbon benefit will vanish in the noise of ever-heavier multimodal datasets. That, again, draws policymakers back into the frame.
Policy Levers: From Carbon-Weighted Schedules to Efficiency Standards
Conventional wisdom suggests that regulators should cap total computing or impose carbon taxes. However, a more effective strategy could be establishing transparent, enforceable efficiency standards, such as 'megajoule per million tokens' targets similar to automobile miles-per-gallon rules. Without transparency, it is impossible to audit this metric, making the current confidentiality around AI energy data a policy failure. Sasha Luccioni and colleagues argue for mandatory ESG-style reporting for AI systems; shockingly, over 80% of large language models released in 2025 still do not provide energy disclosures. This lack of transparency hinders our ability to address AI's energy consumption effectively.
A second lever is carbon-weighted scheduling. Data-center workloads can be orchestrated to exploit low-carbon electricity windows, shifting training jobs to midnight hydropower or surplus solar at noon. The constraint is political rather than technical; grid operators already publish real-time intensity data, but cloud providers seldom expose that signal to users. Providers would pivot overnight if education ministries procured cloud credits based on grams of CO₂ per kiloton rather than raw price.
Finally, governments could condition public research funding on demonstrable efficiency milestones, analogous to the U.S. Department of Energy's Exascale program, which tied grants to performance-per-watt metrics. Universities wishing to boast AI laboratories must invest in heat-recapture systems, building-integrated photovoltaics, or district heating partnerships with municipal utilities to offset their GPU arrays.
The Education Sector's Stake: Beyond Digital Literacy to Energy Literacy
Higher education was an early adopter of cloud computing because it believed bits were cleaner than bricks. Today's campus CIOs face a new accountability ledger. A university deploying a multimodal tutor across 30,000 students at ten queries per student per day could quietly consume 30 MWh per semester—roughly enough to power every dormitory's lighting for the same period. Embedding carbon-cost dashboards into learning analytics would turn abstract externalities into actionable course design decisions: Do you need a high-resolution image generator for every pop quiz? Could a distilled local model suffice for offline grammar correction? Pedagogical benefits must be weighed against environmental debt.
Curricular reform must follow. Engineering programs talk about algorithmic efficiency but seldom connect Big-O notation to kilowatt-hours. Business schools celebrate data-driven innovation but overlook Scope 3 emissions in digital supply chains. The next generation of instructional designers should treat computing cost as a design constraint as crucial as cognitive load.
The Moral Arithmetic of Compute
Of course, there is a socio-economic wrinkle: the marginal carbon intensity of electricity varies wildly by region. Training a model in Iceland's geothermal grid can be up to thirty times cleaner than powering the same GPUs on Poland's lignite-based mix. That asymmetry invites accusations of "carbon laundering," where companies chase low-carbon regions without investing in genuine efficiency. A global registry that tracks watt-hours, timezone, and grid carbon intensity could discourage mere geographic arbitrage.
The deeper ethical question concerns opportunity cost. Every megawatt diverted to synthetic text is unavailable for heat pumps or electric buses. If we aim to mitigate climate change, then the social utility per kilowatt matters. Re-ranking search results or composing marketing copy is not equivalent to decoding protein structures or forecasting storms. Policymakers could introduce a sliding scale of permissible energy budgets tied to societal benefit metrics, effectively rationing compute toward missions with higher public interest scores. Such schemes echo historical broadcast-spectrum allocations and could be managed by independent technology commissions.
Toward an Ethics of Computational Frugality
Human society's evolutionary arc toward immersive virtual spaces is irreversible; synthetic environments are already the classrooms, marketplaces, and civic squares of the twenty-first century. But the arc's carbon imprint is negotiable. With deliberate design, we can make each floating-point operation pull its weight in environmental terms. The path runs through three interlocking terrains: algorithmic austerity, hardware innovation, and policy scaffolding that rewards efficiency rather than brute-force scale.
Algorithmic austerity means favoring sparse, specialized architectures over indiscriminate gigantism; hardware innovation means coupling those architectures with accelerators optimized for energy, not raw FLOPs; policy scaffolding means mandating transparency, instituting efficiency floors, and guiding public dollars toward green AI. Together, they compose an actionable agenda that can shrink AI's carbon curve even as digital demand climbs.
The alternative—a laissez-faire binge on ever larger, more power-hungry models—would lock education and every other sector into a debt of carbon that no number of paperless lectures can repay. Reining in that trajectory is not a technophobic retreat but a sophisticated recalibration of progress. In the end, intellectual growth need not come at thermodynamic expense; we only have to insist that intelligence, artificial or otherwise, learn to live within its planetary means.
The Economy Research Editorial
The Economy Research Editorial is located in the Gordon School of Business and Artificial Intelligence, Swiss Institute of Artificial Intelligence
References
Chen, S. (2025). Data Centers Will Use Twice as Much Energy by 2030—AI-driven. Scientific American.
International Energy Agency. (2025). AI Is Set to Drive Surging Electricity Demand from Data Centres While Offering the Potential to Transform How the Energy Sector Works.
Luccioni, S. et al. (2025). AI Carbon Emissions Remain Unknown as Companies Withhold Energy Data. Wired.
Nakamura, T. et al. (2025). Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization. arXiv preprint arXiv:2502.19261.
Semianalysis. (2024). 100,000 H100 Clusters: Power, Network Topology, Ethernet vs. Infiniband.
Tom's Hardware. (2023). Nvidia's H100 GPUs Will Consume More Power Than Some Countries.
Wired. (2025). AI Is Eating Data Center Power Demand—And It's Only Worse.
Zheng, L. et al. (2025). Sparse Mixture of Experts as Unified Competitive Learning. arXiv preprint arXiv:2503.22996.




















