When "Discoveries" Are Just Big Labyrinths: What an AI Exercise Teaches Us in Pure Math for Education, Evidence, and Hype

Input
Modified
A recent wave of coverage claimed that Reinforcement Learning (RL) had leaped pure math by navigating the notoriously thorny Andrews-Curtis landscape, downplaying long-term potential counterexamples and hinting – breathlessly – at tools that could one day predict stock crashes, pandemics, and even climate disasters years in advance. The research team made progress: by combining the RL standard with intelligent motion compression ("supermoves"), they found paths through cases that had resisted search for decades. But read beyond the headlines, and the story is more straightforward and shorter than the hype suggests. The pre-publication itself reports progress on the scale of thousands of steps — not the billions that speculation allows — that operate with modest calculations and focus on presentation families that are already suspected of being navigable. Caltech's explainer admits that the project neither proves nor disproves the conjecture and explicitly notes that he cannot predict rare events that shape the world. Regulators, meanwhile, warn that AI's forecasting requirements in finance remain fragile. In other words: a thoughtful, well-executed search experiment in a hard combinatorial space – valuable, didactic, and demarcated – mistakenly as a crystal ball. For education policy, the course is not about forecasting; It's about how we teach computational science soberly, reproducibly, and without metaphors that precede mathematics.
Redefining Achievement: From Solving a Maze to Curriculum Design
This work redefines guided search as a modern exercise focused on long horizons rather than general forecasting. It transforms static puzzles into dynamic processes, testing software against sparse reward problems. The study serves as a methodological and educational resource, illustrating search behaviors when short-horizon methods falter and how action sequence compression (hypermovements) can be beneficial.
This perspective is crucial as universities integrate "artificial intelligence" into curricula. By framing this project as a unique "practice of computer science," we celebrate algorithmic art while remaining grounded in reality, helping students distinguish between hype and actual applicability.
Progress is assessed not by headlines or elegance but by methods surpassing baselines, transparency in computational budgets, and independent confirmation. The report shows mixed but encouraging results, with greedy search methods surpassing standard RL baselines and emphasizing modest computing resources. Independent studies also affirm the reproducibility of broader search histories, providing educators with clear baselines and careful validation to build upon.
What the study did - and what didn't
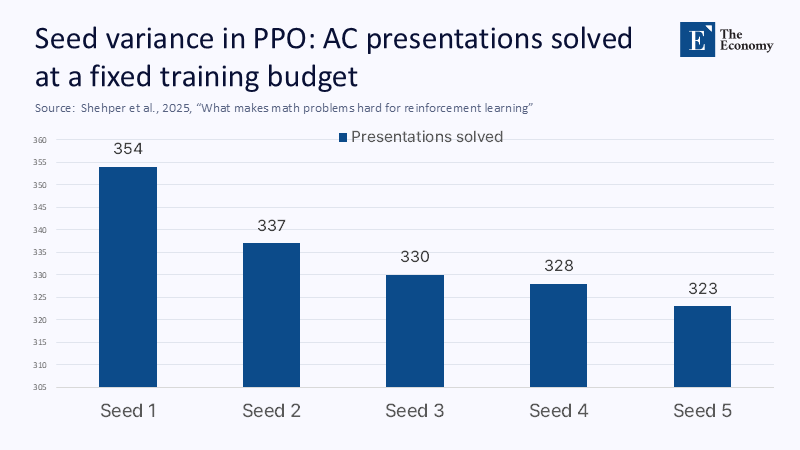
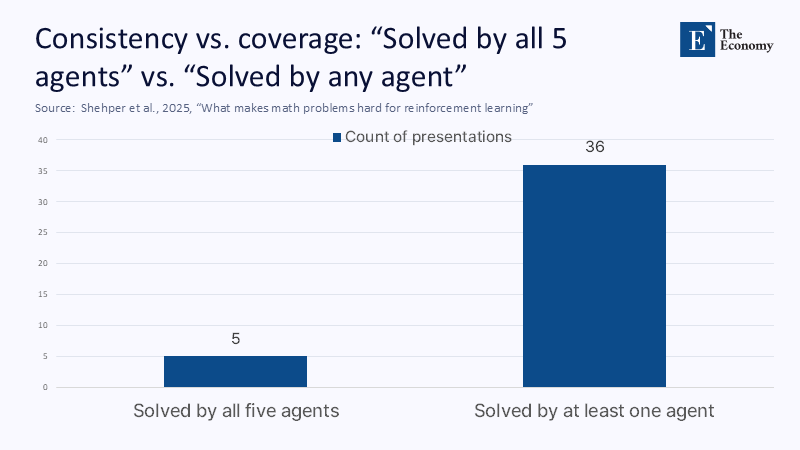
The technical core is simple. The team framed selected cases related to the Andrews-Curtis conjecture as a large-scale decision-making process. The off-the-shelf PPO struggled, while a greedy algorithm with sector-aware modifications fared better. Then, a two-agent scheme learning 'hypermovements '- a term used to describe a technique that compresses multi-step sequences into larger, learning leaps-was employed. This cocktail solved large families of previously unresolved potential counterexamples and simplified others that had resisted the search for scope for years. The paper highlights two crucial facts: typical victory paths are thousands of moves today, well below the worst hyperexponential lengths that mathematicians know there may be. And the calculation used was intentionally mediocre so that peers could reproduce results. This is good science: the delimitation of claims to status was explored and brought to the fore, and reproducibility was considered. It is not, however, a general breakthrough in reasoning or prediction – just a better lens into a particular cave.
It also did not solve the conjecture. Caltech's summary explains it clearly: the team aimed to rule out possible counterexamples, not to prove that the Andrews-Curtis are true or false, and they stayed away from traversing the million-step deserts that the most difficult cases may require. The same summary warns that the algorithm "cannot make predictions" of rare economic or epidemiological events. If anything, supplemental evidence outside the RL piece underscores how narrow the achievement is: a pre-publication by the University of Liverpool details an 8,634-motion trivialization sequence for a Miller-Schupp presentation found with an automated theorem proving over 74 days and 56 GB of memory—again, a tour-de-force of persistent searching, not prophetic modeling. This is precisely the kind of "master's-level geeky exercise" that belongs to a seminar of advanced algorithms: technically demanding, reproducible, and limited domain.
Raw Brain Power: Guided Search, Not General Insight
To call the approach "brute force" is both fair and unfair. It's fair to say that the proven benefits come from searching huge spaces for longer and smarter – compressing sequences of movements, difficulty programming, and learning value cues that make rare hits less rare. It is unfair if "brute force" is perceived as a naïve enumeration. That did not happen. The paper carefully compares standard search methods, shows why BFS collapses below the length of the horizon, and justifies why curriculum-style training and motion synthesis are natural corrections. In the language we need to teach undergraduate students, this is dynamic optimization combined with aggressively constructed heuristics that respect the algebraic symmetries of the problem. It's a well-crafted case study of what RL is buying you: a data-driven policy that amortizes the cost of exploration in many relevant cases. But a policy on presentations is still just that – a learned search policy. It doesn't "understand" conjecture any more than Dijkstra's algorithm "understands" a road map.
For teachers and administrators, two implementation details matter. First, the authors make their code available and repeatedly emphasize the reproducibility of small labs. This invites reproduction, benchmarking, and extension at the course level without hyperscale budgets. Second, their comparative results show a humble reality that we need to elevate in our teaching: sometimes a simple greedy process, coordinated by domain knowledge, goes beyond the standard RL out of the box. This is an excellent instructional moment. Students should learn to draw resections, test on clean baselines, and resist the reflex to reach modern machines before attempting simpler searching. An "AC environment" lab module of the department—download the repository, replicate the greedy curves versus PPOs, and then challenge students to invent a better supermove compressor—would have more educational value than any speculative claim about purchases or hurricanes.
Why the advertising campaign is jumping to predictions - and why politics must resist
The leap from the labyrinths of mathematics to market crashes is rhetorically seductive: both look like far-reaching, sparse reward systems. But even proponents admit that the generalization from symbolic domains to noisy, conflicting, non-stationary systems is a gap. Financial regulators and international organisations have explicitly expressed the limits and risks: the Financial Stability Board warns that genetic AI introduces new inaccuracies and opacity, complicating risk assessment; the ECB notes that AI can weaken risk functions if its forecasts are unreliable; and the IMF warns that AI-powered speed can amplify volatility, requiring new safeguards. These are not anti-innovation positions; They are anti-hype positions that are aligned with the evidence. The gap between solving a labyrinth where the rules are stable and envisaging a complex adaptive system is not a matter of "more steps", but of incorrect model specifications, regime changes, and incentives. Education policy must treat the gap as a feature of the curriculum and not as a mistake.
The empirical literature also tempers the excitement. Meta-analyses and critical reviews over the period 2024-2025 continue to find that machine learning models to predict conflicts or crises often fail to translate statistical significance into an out-of-sample, economically significant advantage, especially between regimes. Meanwhile, competitions show that human superforecasters are still beating AI systems in many real-world prediction tasks, even when the gap is narrowing. The right attitude for academic programs and school systems is strict pluralism: teach RL search alongside strong statistics, causal inference, and decision theory. Show students why plausible models collapse under regime change. They require interpretability workshops that emphasize fidelity over persuasion. A culture that enables students to challenge claims — especially claims ranging from math to markets — will produce graduates who can say "not yet" as confidently as they say "I can replicate this."
What we need to change in classrooms and communications
First, incorporate computer science as a key component in education. The SIAM 2024 Panel emphasizes the importance of computing at the intersection of mathematics, AI, and high-performance computing. Curricula should include literate programming tasks that replicate research data, link calculations to outcomes, and score basic thinking. Students should express optimization methods in plain language, and framing reinforcement learning (RL) as a "quest driven by a values learning landscape" will help clarify claims.
Secondly, update communication rules on campus. Press releases should avoid suggesting external generalizations without evidence. If studies can't predict rare events, they shouldn't be used to make broader claims. A guideline for communications could be to accompany outward metaphors with statements about their limitations. For instance, Caltech's warning about scope is commendable, while popular media often lacks this rigor.
While some argue that methods can be scaled, evidence does not support the leap from group presentations to complex predictions in areas like economics or epidemiology. Educational institutions should prioritize clear boundaries in research and incentivize methodical expansions of knowledge. By modeling this clarity, graduates can carry it into their future roles in labs, companies, and public discussions.
What Real People Say – And How To Teach With It
Skepticism about "artificial intelligence discoveries" based on brute force is widespread beyond academia. A widespread discussion at the forum in 2023 framed much of modern AI as "brute force machine learning," pushing research toward local optimization while confusing fluency with understanding. This view is too cynical in terms of its authoritarianism, but valuable in terms of its corrective action; It expresses rules that we must cultivate in the classrooms: we insist on basic comparisons, we treat calculation as a scientific variable, and we separate prediction from persuasion. When a critical blog post dismisses the math result as a "geeky school exercise," the appropriate response to education is not defensiveness but planning: turn the exercise into a culmination where students reproduce the curves, measure sensitivity to reward configuration, and document when and why the greedy beat the PPO. If done well, skepticism becomes pedagogical.
Teach the maze, ignore the crystal ball
The strongest statistic in this story is not the number of solved cases. It's the gap between what the method can do and what the titles promised. Thousands of moves in symbolic labyrinths are a triumph of patient, structured search, not a license to predict systemic shocks. Calibrated correctly, the achievement is ideal for education: a reproducible sandbox for teaching long-term optimization, a stage for honest comparison of search baselines, a reminder that computational budgets and code liberation are part of the scientific method. The policy move is simple: invest in computational science literacy, require field demarcation statements in research communications, and ban transfers ranging from mathematics to markets without proof. If we teach the maze as a maze – finite, bound by rules, and navigable with the right heuristics – students will learn to build better lenses. If we sell it as a crystal ball, we are training a generation to confuse brilliance with insight. The first strengthens the institutions. The latter inflates bubbles. Choose the first one.
The Economy Research Editorial
The Economy Research Editorial is located in the Gordon School of Business and Artificial Intelligence, Swiss Institute of Artificial Intelligence.
References
Aldasoro, I., et al. (2024). Intelligent financial system: how AI is transforming finance. Bank for International Settlements Working Document No. 1194.
Bank of England. (2025). Financial Stability in Focus: Artificial intelligence in the financial system (April).
Béchard, D. E. (2025, August 11). How an unsolved mathematical problem could train artificial intelligence to predict crises years in advance. Scientific American.
Crisanto, J. C., et al. (2024). Regulation of artificial intelligence in the financial sector: recent developments and points to consider. BIS FSI Insights No. 63.
European Central Bank. (2024, May 16). The rise of artificial intelligence: benefits and risks for financial stability. ECB Financial Stability Overview, special feature.
International Monetary Fund. (2024, September 6). Artificial intelligence and its impact on financial markets and financial stability (observations).
Lisitsa, A. (2025, January 17). The automated proof of theorems reveals a long Andrews-Curtis trivialization for a trivial Miller-Schupp group presentation. Προδημοσίευση SSRN.
Perez, C. E. (2017, September 23). Is deep learning innovation only due to brute force? Medium (intuition machine).
Romary, E., &; Zupan, A. (2024, February 19). An Andrews-Curtis family trivializes through 4-multiple three-dimensionals. Dedicated Geometry, 218, 45.
Shehper, A., Medina-Mardones, A. M., Lewandowski, B., Gruen, A., Kucharski, P., Qiu, Y., Wang, Z., &; Gukov, S. (2024, August 27). What Makes Math Problems Difficult for Reinforcement Learning: A Case Study. arXiv pre-publication 2408.15332; AC-Solver code repository.
This is Caltech. (2025, February 13). The AI program is playing the long game of solving decades-old mathematical problems (press release).
Vox. (2025). Why Humans Are Still Much Better Than Artificial Intelligence in Predicting the Future.
Y Combinator / Hacker News. (2023, January 30–February 1). Thread of discussion on whether modern AI is "just brute force".





















Comment