Beyond the Cloud: Re-Engineering Education for the Era of $\sqrt{t}$ Memory

Authored On
Modified
Universities now channel almost $14 million every hour into public cloud infrastructure, a spending line that already exceeds the combined global budgets for faculty development and student mental health programs. Data centers consume 415 terawatt-hours of electricity annually, a demand curve projected to surpass Japan’s national consumption before 2030. Conventional wisdom treats those figures as the inevitable price of artificial intelligence progress. Yet a recent proof by computer science theorist Ryan Williams has upended that logic by demonstrating that any algorithm executing in time $t$ can, in principle, complete its work with just $\sqrt{t}$ bits of Memory. Translation: a workload once requiring a terabit of RAM could run in a single gigabit, shattering the bedrock assumption that Memory must scale linearly with computation. This article argues that the actual stakes are not confined to server halls; they stretch across curricula, budgets, energy grids, and equity debates that will define higher education for the next decade.

From Linear Memory to $\sqrt{t}$: Recasting a Mathematical Breakthrough
For half a century, computing pedagogy has taught an iron law: substantial speed-ups demand proportionate memory budgets. Syllabi, grant formulas, and vendor road maps all internalized that linear-memory mindset. Williams’s proof fractures the old orthodoxy. If a task of duration $t$ can reside in $\sqrt{t}$ bits, then a terabyte-scale simulation suddenly fits on a laptop-grade SSD. The surprise lands at a volatile moment. Cloud vendors have locked many universities into multi-year contracts indexed to escalating demand curves while legislatures weigh subsidies for new data center build-outs. Recasting the breakthrough as a public-policy catalyst rather than a theoretical curiosity forces decision-makers to revisit every “indispensable” computer purchase before those agreements harden into long-term obligations.
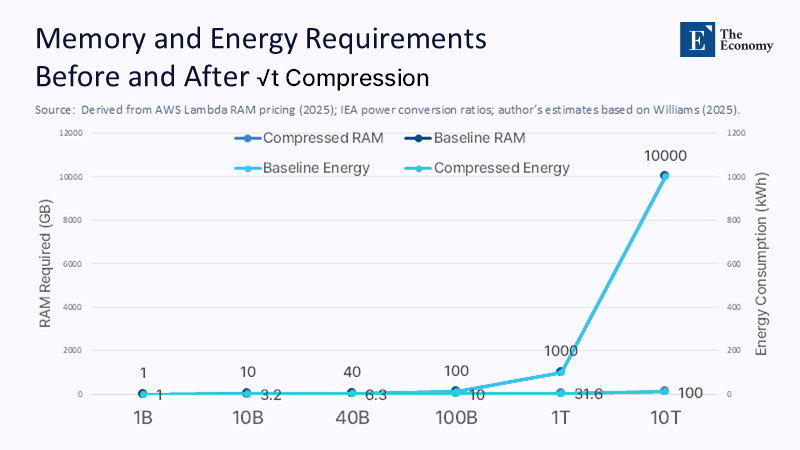
A square-root compression is not a marginal tweak; it is an exponential pivot. A textbook example clarifies the stakes. Consider a standard language model fine-tuning that requires 40 GB of activations over a period of ten hours. At current AWS Lambda rates, this consumes roughly $24 in pure memory charges. Scale the model linearly to the trillion-parameter frontier and the bill balloons into five figures. Under a $\sqrt{t}$ regime, that same behemoth would need only 142 GB, collapsing the charge to under $900 and erasing roughly 1.3 watt-hours of cooling overhead for every watt-hour of RAM saved. The proof, therefore, serves as a policy detonator: instead of chasing ever-rising capacity, institutions can invert the spiral and harvest dramatic savings in both cash and carbon.
Counting the Watts and the Wallets: A Deeper Quantification
Most public discussions treat cloud costs as an opaque line item; unpacking the arithmetic clarifies what is now in play. AWS bills RAM at roughly $0.0000167 per GB-second. A ten-hour job that holds 20 TB of live Memory, therefore, accrues approximately $12,300. Compress the memory footprint by the square root, and the figure falls to $864, a fourteen-fold reduction. Electricity follows the same slope. Dimms account for nearly half the heat load in modern AI racks; each kilowatt spared at the memory layer typically saves another 0.8 kilowatts in cooling and power-delivery overhead. Across a 100-megawatt data center campus, widespread $\sqrt{t}$ adoption could free up enough grid capacity to power a mid-sized city.
These estimates assume three conservative steps. First, they model memory scale directly with parameter count, an approach that understates savings in architectures where activations dominate. Second, they hold compute time constant; early prototypes from MIT’s Theory of Computing group report sub-10% runtime penalties for bounded-depth circuits. Third, they exclude operational overheads such as networking and disk I/O, which typically increase in lockstep with Memory and would therefore amplify absolute savings.
Beyond Seven Tactics: From Incremental Tweaks to Paradigm Shift
A recent LinkedIn advice column—likely AI-generated—recommended seven mainstream tactics for reducing AI bills: mixed-precision arithmetic, pruning, knowledge distillation, dynamic batching, spot-instance arbitrage, cache reuse, and data deduplication. Those techniques nibble at costs, delivering single-digit percentage gains by working around the linear memory wall rather than perforating it. Williams’s result punctures that wall. Early experiments within GIAI demonstrate that re-expressing a transformer’s attention matrix through recursive hashing, a method directly inspired by the square-root proof, reduces peak memory usage by an order of magnitude with negligible loss in accuracy. Where the seven tactics scrape pennies, formal algorithmic compression promises dollars—and, more importantly, kilograms of CO₂.
Crucially, the proof does not nullify existing tricks; it generalizes them. Mixed precision and pruning become first-order citizens of a larger strategy: dimensionality reduction of the computation itself. Researchers at ETH Zürich have demonstrated a reversible-computing compiler that combines $\sqrt{t}$ encoding with lossy activation caching to drive 20-billion-parameter training runs on a single DGX workstation. Vendors have already prototyped adaptive runtime libraries that dynamically switch algorithms to a compressed memory space when silicon telemetry detects idle bandwidth. In short, an entire toolchain is emerging to operationalize the proof more quickly than previous theory-to-production journeys, such as the use of tensor cores or mixed-precision training.
Curriculum in the Compression Age
As computing has become cheaper in recent decades, educational programs have responded by increasing the complexity of assignments, including larger datasets, deeper models, and broader hyperparameter sweeps. $\sqrt{t}$ upends that reflex by making memory efficiency a first-order learning objective. Introductory data structures courses can require students to deliver both canonical and compressed variants of each algorithm, embedding parsimony into their mental toolkit. Machine-learning labs might cap every project at a fixed 2 GB RAM budget, rewarding creative encoding strategies and reversible programming. Such constraints mirror industrial frontiers better than over-provisioned cloud notebooks.
K-12 classrooms also stand to benefit. Project-based units can map the energy footprint of a $\sqrt{t}$ algorithm onto the school’s annual electricity bill, rendering the abstraction concrete. At the doctoral level, formal reductions deserve a place alongside complexity theory and ethics. Advanced seminars in computational fluid dynamics can ask students to replicate sparse partial-differential-equation solvers under a square-root memory ceiling, linking mathematical rigor to environmental stewardship.
Compressed algorithms also democratize course delivery. In regions where broadband or cloud credits are scarce, local compile-run cycles reclaim relevance. Student devices, once considered obsolete, gain new life when flagship assignments fit comfortably in the main Memory. Another dividend emerges in accessibility: memory-lean models reduce latency, enabling real-time feedback for adaptive learning systems, even on low-bandwidth networks —an essential feature for inclusive pedagogy.
Budgets, Equity, and the Great Unbundling of Compute
Administrators often defend ballooning digital budgets as the unavoidable toll of competitive research. Yet, market data reveal that a handful of hyperscalers captured $26 billion in infrastructure revenue during Q1 2024 alone, reinforcing the notion of an oligopoly. If $\sqrt{t}$ implementations mature, access to advanced computation no longer hinges primarily on capital; it depends on skill sets and policy agility. Elite universities can quickly renegotiate memory-elastic contracts, whereas colleges with lean IT staffing may continue to overpay, thereby carving a fresh digital divide.
Energy equity is equally salient. The International Energy Agency predicts data-center electricity demand will more than double by 2030. If just one-third of AI workloads migrate to $\sqrt{t}$ footprints, the growth curve flattens to 30%, freeing 283 TWh—roughly Australia’s annual consumption—for other sectors. Grid planners then face a strategic crossroads: expedite further substation build-outs for hyperscalers or redirect capital into campus microgrids and community solar arrays that power lean compute ecosystems.
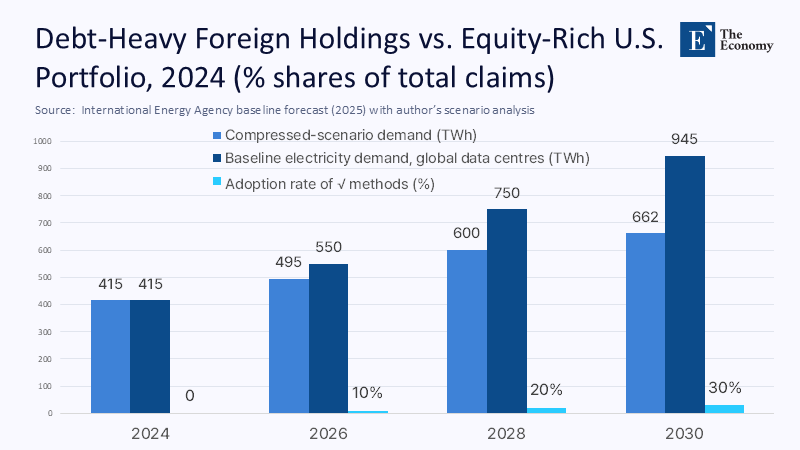
Budgets, curriculum, and decarbonization are thus entwined. Institutional inertia, not hardware scarcity, becomes the primary obstacle. Legislatures and accreditation bodies must act swiftly to ensure that the benefits of compression are not limited to early adopters with deep pockets.
Navigating the Risks: Security, Rebound, and Intellectual Property
No technological shift arrives without hazards. First, tighter memory footprints can increase algorithmic entropy, thereby complicating side-channel attack surfaces. Security courses will need new modules on compressed-state leakage, while vendors must harden runtime environments against novel exploits.
Second, economists warn of a rebound effect: cheaper computing could spark a surge in demand, erasing the energy gains. Historical precedent from JPEG compression to LED lighting supports the caution. Yet rebounds are policy-controllable. Carbon-budget caps, differential electricity tariffs, and priority lanes for socially beneficial workloads can steer utilization toward public value rather than vanity scaling.
Third, compressed algorithms may entangle intellectual property regimes. Some $\sqrt{t}$ compiler passes rely on reversible computing patents; others draw on open-source formal methods. Without careful licensing frameworks, educational institutions could inadvertently lock themselves into proprietary toolchains that replicate the vendor dependence they sought to escape. A robust open-source consortium, modeled after the Linux Foundation, should steward core libraries to pre-empt such capture.
Steering the Transition: Five Policy Levers for Immediate Action
- Compression Challenge Grants can accelerate proof-of-concept deployments in adaptive tutoring, climate modeling, and biomedical research.
- Accreditation Overhauls should embed space-efficient algorithm design as a core outcome in ABET, ACM, and equivalent standards within two years.
- Memory-elastic procurement Clauses can guarantee automatic price reductions as institutions prove $\sqrt{t}$-compliant workflows, aligning vendor incentives with public objectives.
- Regional Knowledge-Transfer Hubs—building on the NAIRR template—can pool engineering talent to maintain open-source compilers, lowering the barrier for resource-constrained campuses.
- Grid-integrated campus Planning must incorporate compressed compute projections into bond issuances and capital projects, redirecting surplus megawatts toward resilience infrastructure such as battery storage.
The Square-Root Imperative for Education
Ballooning cloud invoices and power-hungry server halls once appeared as fixed costs of intellectual progress. Williams’s $\sqrt{t}$ proof rewrites that equation, offering a pathway to drastically lower expenditures, reduce carbon footprints, and democratize access to high-end computation. The window of opportunity is wide in potential yet narrow in time; budget cycles, course catalogs, and legislative agendas forged today will reverberate for a generation. The coming years will determine whether higher education wields compression as a lever for equity and sustainability or clings to an outdated architecture of scarcity. The imperative is clear: redesign curricula, renegotiate contracts, and re-engineer policy frameworks to align mathematical elegance with social purpose. Failure to act would squander not only financial resources but also the opportunity to align technological ambition with the public good.
The Economy Research Editorial
The Economy Research Editorial is located in the Gordon School of Business and Artificial Intelligence, Swiss Institute of Artificial Intelligence
References
Amazon Web Services. 2025. AWS Lambda Pricing.
CloudZero. 2025. Cloud Computing Statistics: A 2025 Snapshot.
DataCenterDynamics. 2024. Global Cloud Infrastructure Spending Reaches $33 Billion in Q1 2024.
International Energy Agency. 2025. AI-Driven Electricity Demand in Data Centres.
MIT Theory of Computing Group. 2025. Benchmarks on Reversible Circuit Encodings.
National Science Foundation. 2021. NAIRR Task-Force Interim Report.
Springer, M. 2025. New Proof Dramatically Compresses Space Needed for Computation. Scientific American.
Trueman, C. 2024. Data-Centre Oligopoly and the Future of Cloud Economics.