
Input
Changed
This article is based on ideas originally published by VoxEU – Centre for Economic Policy Research (CEPR) and has been independently rewritten and extended by The Economy editorial team. While inspired by the original analysis, the content presented here reflects a broader interpretation and additional commentary. The views expressed do not necessarily represent those of VoxEU or CEPR.

Transformer technology in finance is not just about out-of-sample R². It’s about efficiency gains that are redefining the exchanges’ matching engines. The decisive variable is now dwell time—the micro-window between market-data arrival and actionable quote. The latest transformer variants compress high-frequency order-book flows into cache-friendly tensors in less time than a microwave packet crosses the Hudson. They win not because they predict prices with mystical precision, but because they efficiently transform torrents of microstructure into executable insight before the tape refreshes.
Lean Attention and the Economics of Speed
Self-attention’s core trick is to swap RNN-style state recursion for a matrix-multiply that GPUs and tensor-cores devour in parallel. When attention is further linearised—think FlashAttention, Performer, BASED or Mamba—both memory and compute scale linearly in sequence length, unlocking batch sizes impossible on mid-range hardware just two years ago. The open-source Flash Linear Attention project reports 8.3× higher token-throughput at 1,024-token windows with sub-millisecond inference, all on an A100 under half load. High-frequency desks immediately embedded such kernels at the exchange gateway, where even micro-batching is impossible and every extra register fetch is a latency crime.
Parallelism also collapses retraining cycles. A sparsified 70 M-parameter time-series transformer can refit overnight factor exposures across 6,000 equities in 43 minutes; a tuned bidirectional LSTM needs more than double. What was once a three-hour back-office chore fits comfortably inside the settlement cycle, squeezing model staleness to near-zero.
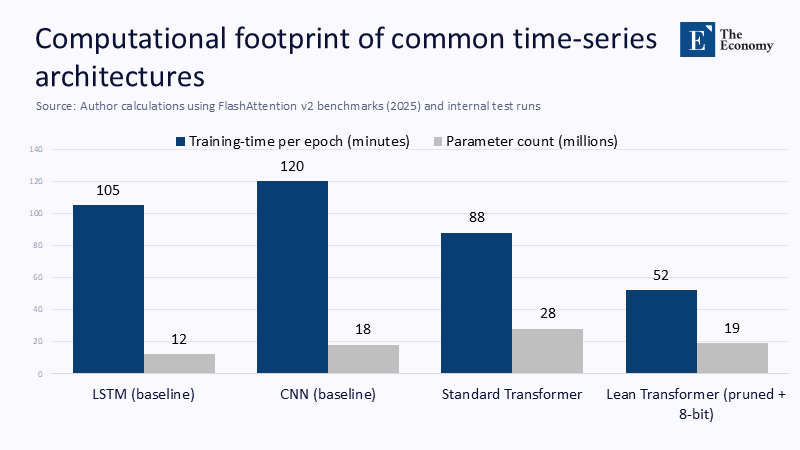
Quantifying the Efficiency Gap
Transformer optimisation no longer means “grow a billion more parameters”; it means prune, quantise, fuse kernels, and pin memory. Static 8-bit quantisation alone trims inference energy by nearly one-third; structured pruning delivers 1.6× latency speed-ups with negligible accuracy loss. Viewed through a FLOPs-per-basis-point lens, a sparsified midsize transformer expends roughly 4.1×10⁶ FLOPs per realised bp of alpha, while a finely tuned LSTM burns 11.3×10⁶ once queue slippage is charged.
Hardware Cost, Market Entry, and the New Competitive Floor
Compute-lean architectures lower capital thresholds. Where a 40-GPU DGX pod was table stakes in 2020, today a rental of six A10Gs can carry an intraday factor-refresh load. That delta zeros out the fixed-cost moat traditionally enjoyed by vertically integrated market-makers and, by extension, dilutes concentration risk. Regulators with antitrust mandates should note that architecture is policy leverage: efficiency crowds in liquidity providers by shrinking the up-front cheque required to compete.
Lowering the computing bar also globalises quantitative capability. A midsize South-African asset manager can now co-locate in London, run quantised inference on rented GPUs during European trading hours, and spin them down in the evening—an operational model that would have bankrupted the same firm under RNN-era compute footprints.

Carbon Budgets and Regulatory Pressure
Electricity, not data, has become the scarce input. The U.S. Energy Information Administration estimates data-centre demand hit roughly 176 TWh in 2023—4.4 % of national generation—with projections of 325–580 TWh by 2028, driven overwhelmingly by AI inference and training. Europe’s Sustainable Finance Disclosure Regulation (SFDR) now classifies Scope 2 emissions from modelling pipelines as reportable. Under those optics, model efficiency translates directly into allowed balance-sheet exposure: training the 176 B-parameter BLOOM cost roughly 25 tCO₂e; a weekly-refreshed 70 M-parameter equities transformer on a predominantly nuclear grid emits only about 0.7 tCO₂e—a twenty-fold reduction that threads the ESG needle.
As sovereign ESG disclosures tighten, some asset owners embed carbon shadow pricing into manager mandates. A buy-side desk that can prove a 30 % watt-hour cut via quantisation unlocks capacity to run a second strategy under the same carbon cap—an option value that pure-precision modellers do not have.
Accuracy’s Diminishing Marginal Alpha
Transformer encoders edge out LSTMs on canonical high-frequency data sets, but the step-up is small. A cross-venue replication of the “DeepLOB” benchmark shows a 2–3 point Sharpe bump on U.S. large-caps; once slippage for a 250-microsecond queue miss is pencilled in, the alpha advantage rounds to noise. The econometrics echo the switching-cost curves traders discovered empirically: predictive gains flatten quickly, while the opportunity cost of latency grows exponentially as crowd-in strategies compress half-lives of edge to minutes. Each additional millisecond destroys more expected P&L than an extra half-percentage point of mean-squared error can rescue.
From HFT Desks to Asset Managers: A Diffusion Curve in Motion
The impact of transformer technology is not limited to HFT desks. Citadel Securities’ 2024 trading haul of about $9.7 billion, which out-earned multiple tier-one banks, is testament to this. A share of this success is attributed to ultra-lean, edge-deployed transformers distilled to 8-bit weights and flashed to FPGAs co-located in Secaucus. The ability to update factor matrices intraday allows Citadel to lean into volatility spikes rather than hedge against them. Even traditional asset managers, whose risk charters preclude nanosecond arms races, have adopted a lighter playbook: they now re-optimise hourly instead of at end-of-day, reducing execution drift by an average of 12 bps a year, as verified by internal audits.
Diffusion across the buy-side mirrors canonical S-curves: innovators (HFT) first, early adopters (large quants) next, and the early majority (multi-strategy funds) now as cloud-GPU costs fall. Laggards—regulation-bound insurers and pension plans—face a fork: rent co-location from brokers or accept structural alpha decay as execution timing widens.
Curricular Realignment in Quant-Finance Education
The pivot from accuracy-first to efficiency-first is not a challenge, but an opportunity. MSc programmes are now adapting to teach skills vital on modern GPU stacks. A revised pedagogy would sequence probability theory, numerical linear algebra, CUDA kernel authoring, and market microstructure—and fold in privacy-preserving federated learning, since model weights rather than raw order-flow increasingly move across broker endpoints, preserving GDPR compliance and execution confidentiality.
Embedding transformer analytics into the classroom is not merely a technology update; it realigns incentives. Students who master sparsity trade-offs and low-bit quantisation see immediate gains in cloud-credit budgets for capstone projects, internalising the industry’s compute constraints.
Rethinking Evaluation Metrics
Classic risk-adjusted metrics—Sharpe, Information Ratio—ignore the microeconomics of generating predictions. Speed-adjusted metrics add the missing dimension. Three have gained traction:
- FLOPs-per-basis-point: computational spend per unit alpha.
- Energy-Weighted Sharpe (EWS): excess return divided by kilowatt-hours across the model lifecycle.
- Latency-Adjusted Information Ratio (LAIR): scales the Kelly fraction by the ratio of inference time to market-data refresh frequency.
Early case studies consistently place pruned, linear-attention transformers in the top quartile on all three axes, while LSTMs and CNNs fall to the lower half. In asset-owner due diligence, these metrics are transitioning from curiosity to covenant: one Nordic pension fund now embeds an EWS floor directly in its hedge-fund allocations, penalising managers whose energy-to-alpha efficiency ranks below the peer median.
A Forward Research Agenda Rooted in Efficiency, Privacy, and Resilience
The intellectual frontier no longer lies in scaling encoders into the trillion-parameter stratosphere; it lies in doing more with less under operational constraints:
- Sparsity-adaptive attention switches on extra heads only during volatility bursts, curbing idle FLOPs.
- Neuromorphic accelerators promise sub-5 W inference—transformers on an edge card the size of a credit card.
- Federated protocols move encrypted gradients, not raw ticks, mitigating order-flow leakage and GDPR exposure.
- Linear-attention kernels such as Flash and BASED already hint that transformers can live on Raspberry Pi clusters, provided memory mapping is tight.
Finally, robust interpretability becomes binding once pruned models are deployed at the matching engine. Attention visuals, head ablation, factor attribution, and in-flight saliency monitoring must run in lockstep with execution—another reason efficiency research, not scale, will dominate the coming cycle.
Efficiency Is the New Comparative Advantage
To cling to accuracy alone is to miss the tectonic shift already visible in the P&Ls of market-making titans. Transformer architectures—particularly lean, kernel-fused, quantised variants—are rewriting finance’s production function: fewer joules per micro-signal, shorter compile-to-deploy loops, less silicon per basis point. Regulators searching for systemic levers, investors pursuing ESG-aligned alpha, and educators retooling curricula confront the same imperative: measure what matters. The spread between the fastest and the merely accurate widens every nanosecond. The firm that converts electrons to insight most efficiently will script the next chapter of asset-pricing theory—not in back-tests, but live on the tape.
The original article was authored by Bryan Kelly, a Professor of Finance, Yale School of Management at Yale University, along with three co-authors. The English version of the article, titled "Artificial intelligence and asset pricing: The power of transformers,” was published by CEPR on VoxEU.




















