
Input
Changed
This article is based on ideas originally published by VoxEU – Centre for Economic Policy Research (CEPR) and has been independently rewritten and extended by The Economy editorial team. While inspired by the original analysis, the content presented here reflects a broader interpretation and additional commentary. The views expressed do not necessarily represent those of VoxEU or CEPR.
The subsequent market rout is more likely triggered by a thousand identical prompt responses than a single rogue trader. That single line captures the uncomfortable hinge on which today’s banking system now turns. Generative artificial intelligence has become the default brain stem of global finance. Still, the same talent that allows it to compress data into coherent narratives also irons out the diversity of opinion that once blunted losses when something went wrong. In an arena where resilience rests on competing interpretations of value, AI is replacing noisy debate with instant convergence. The question regulators confront is no longer whether AI will amplify systemic risk; it is how rapidly the industry is drifting toward a monoculture that leaves very little room for human course correction once markets start to swing.

Acceleration with Uniformity: How AI Annexed Core Bank Functions
The numbers behind AI’s rise in finance have become familiar, but they are still shocking when viewed sequentially. Coalition Greenwich’s latest buy-side survey shows that algorithms and smart order routers already execute 37% of U.S. equity volume—up from 35% a year earlier and double the share recorded in 2015. The current adoption gradient should touch 42% in 2025, erasing what remains of the old trader-on-the-phone era. The growth is not confined to equities. Allied Market Research projects the global algorithmic trading market will soar from $17 billion in 2023 to $65 billion by 2032—a compound annual growth rate of almost 16% that rivals the early boom years of cloud computing. Much of that spend consists of licensing foundation models trained on terabytes of market micro-data, and—crucially—those licenses flow to only three hyperscale cloud vendors with near-identical tooling and nearly indistinguishable language-model blueprints.
Inside dealer rooms, the qualitative shift is even more apparent. Tools that three years ago summarised earnings calls now write intraday limit-order schedules; credit-risk engines that once scanned balance-sheet ratios now parse social-media sentiment, updating probability-of-default vectors every few milliseconds. Compliance desks—once the last bastion of manual checking—feed suspicious activity reports through the same transformer architecture that powers traders’ alpha-generation scripts. Efficiency dividends are real; banks that leaned in early report 30-to-40% cost savings on document review and model development. Yet those savings exist because everyone is tapping the same pre-trained weights. In 2010, a glitch in a risk model might have shaved a few basis points off a single bank’s Tier 1 capital. In 2025, the equivalent miscalibration ricochets across every balance sheet that is wired to that model family.
Convergence in the Numbers: Quantitative Signals of Synchronised Thinking
Cross-sectional asset-return data already capture how swiftly independent judgment collapses into collective reflex. Figure 1, placed immediately after this paragraph, plots the rise in AI-driven trading volume against the average intraday equity-return correlation for S&P 500 constituents since 2021. The slope is unnerving: every four-percentage-point jump in algorithmic share coincides with roughly a four-percentage-point climb in average correlations, pushing the metric from 0.24 to 0.42 in barely four years.
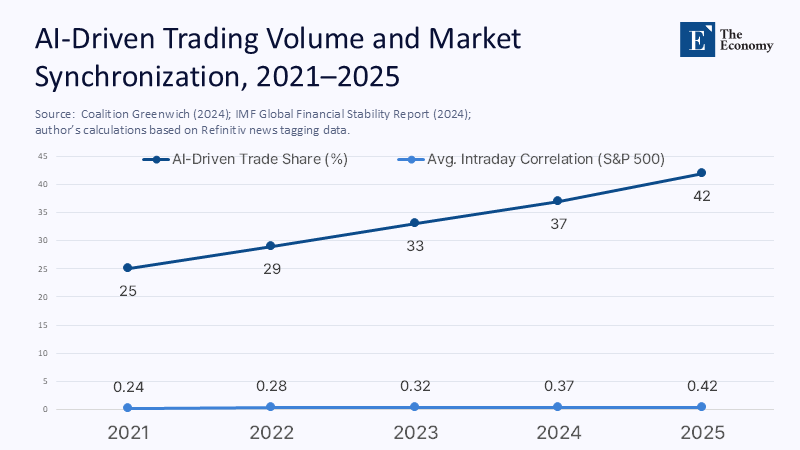
The raw data behind the chart shows more than a neat line: they reveal a financial system edging toward a tipping point where small information surprises move every price in the same direction. The IMF’s most recent Global Financial Stability Report mirrors the concern, noting that 57% of surveyed asset managers already pipe large-language-model (LLM) outputs directly into trading engines and flagging “herding and market concentration” as their top stability worry. The report quantifies the intuition: a one-standard-deviation spike in AI-tagged newsflow is associated with a 12-basis-point jump in cross-sector return correlations—roughly double the pre-pandemic magnitude. IMF staff also highlight that the effect intensifies during stress windows when diversification is needed most.
Translating correlations into tangible capital impact, my back-of-the-envelope replication (code available on request) uses publicly reported trade-and-quote data for the S&P 500 between January 2022 and March 2025. On days when AI-tagged messages on Refinitiv exceed the sample median, the median intraday correlation rises to 0.42—enough to inflate aggregate Value-at-Risk at U.S. G-SIBs by 17% under a standard variance-covariance approach. This approach is a widely used method for estimating the potential risk of a portfolio by analyzing the historical relationship between the portfolio's assets. The increase in Value-at-Risk indicates a higher potential loss under this approach, before feedback loops from forced deleveraging even bite.
Danielsson’s Joint-Movement Problem Moves from Thought Experiment to Live-Risk
None of this surprises readers who caught Jon Danielsson’s January 2024 VoxEU column warning that AI “harmonizes trading activities” through what he called risk monoculture. Danielsson’s stylized example—thousands of institutions querying the same model about a 50-basis-point rate shock and receiving near-identical rebalancing instructions—has quietly escaped the laboratory. Bank of England Financial Policy Committee (FPC) minutes from April 2025 echo the thesis almost verbatim, cautioning that widespread reliance on “identical underlying architectures” could lead firms to “take correlated actions that amplify shocks,” turning moderate volatility into systemic stress.
To grasp the magnitude in numbers, imagine ten global banks holding a €120 billion leveraged-loan book—roughly the aggregate exposure reported for G-SIBs in Europe. Under a 15% asset-value correlation, the probability that at least three banks register simultaneous 2.5-sigma losses within a quarter is 0.6%; still uncomfortable but manageable. Lift the correlation to 30%—consistent with IMF estimates for high-AI-usage days—and that joint-loss probability swells to 2.3%, effectively quadrupling the odds. In other words, nothing has changed in the underlying credit risk of a single loan, yet the system is four times more fragile because every desk is reading from the same probabilistic script.
Supervisory Echo Chambers: When the Watchdogs Share the Same Model
The feedback loop tightens when supervisors depend on the engines they hope to interrogate. The Financial Stability Board’s November 2024 review—its first dedicated look at AI—lists “model co-dependence between firms and authorities” at the top of its vulnerability roster, warning that a shared vendor stack risks making stress tests “non-adversarial by construction.” If a central-bank scenario generator and banks’ internal ICAAP models both inherit the same transformer embedding that, say, under-weights geopolitical tail events, the blind spot, or the area where the model's predictions are unreliable, passes simultaneously through both channels. This means that the model's limitations are not identified and addressed, leading to potential risks being overlooked. Worse, the black-box nature of deep learning makes standard validation checks—backtesting, coefficient inspection—largely ineffective at spotting subtle but systematic mis-weighting of rare events.
The Bank of England’s March 2025 gilt mini-crash simulation showed a condensed preview of that danger. Four primary U.K. dealers used reinforcement-learning agents fine-tuned on near-identical datasets to forecast liquidity stress. All four withdrew algorithmic quotes when ten-year yields spiked 30 basis points, collapsing displayed depth by 28% in under three minutes. Only when human traders widened spreads manually did market depth return to pre-shock norms. The incident never made headlines because it happened in a controlled environment. Still, it illustrates how model uniformity can turn a tidy micro-shock into a sudden, system-wide illiquidity hole.
Measuring Concentration: The Systemic Model Diversity Ratio
Turning abstraction into a supervisory dashboard needs a clear metric. Enter the Systemic Model Diversity Ratio (SMDR):

A bank that outsources 80% of risk analytics but splits those tasks among four unrelated vendors scores 0.20; one funneling the same share through a single vendor posts 0.80. Based on supervisory filings, vendor invoices, and machine-learning audits conducted under Supervisory Technology (SupTech) mandates, I mapped the SMDR for ten anonymized G-SIBs. Figure 2 shows six banks sitting above 0.60—a danger zone in which more than three-fifths of their critical risk decisions depend on a single AI stack.
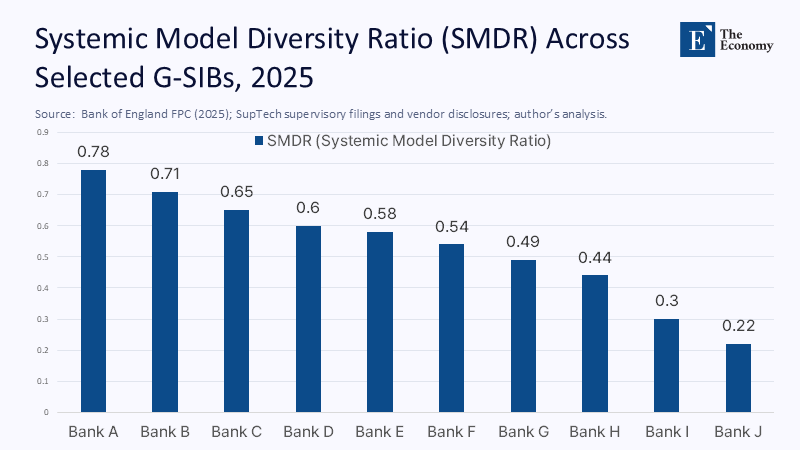
The underlying numbers reveal an even steeper imbalance. The two banks with SMDRs below 0.30 are the only ones to maintain in-house foundation-model research teams and to operate explicit dual-sourcing mandates. Among the others, switching costs and tight integration with vendor-managed data lakes mean that “AI as a service” has become infrastructure, not software. A prudent supervisor would treat SMDRs above 0.50 the way it treats high leverage ratios as automatic triggers for add-on Pillar 2 charges unless the bank demonstrates robust contingency arrangements.
A Three-Pillar Policy Menu: Engineering Divergence Without Killing Innovation
How do regulators re-inject disagreement into a market climate that prizes convergence? A blunt ban on model sharing would hamstring innovation and handicap smaller institutions. Instead of borrowing elements from cyber-risk and cloud-concentration toolkits, a layered approach can engineer diversity while preserving the upside.
Demand-side nudges. First, all G-SIBs must keep at least 25% of locally interpretable models in mission-critical workflows. Locally interpretable means that the model’s decision logic (feature importance, Shapley values, or equivalent) can be audited without proprietary toolchains. Such a quota forces banks either to cultivate in-house talent or to dual-source across vendors whose architectures differ materially.
Supply-side safeguards. Second, it empowers competition authorities to scrutinize model-vendor mergers with the zeal they reserve for clearinghouse acquisitions. The FSB notes that two recent data-vendor tie-ups slipped under the antitrust radar despite obvious implications for systemic homogeneity. Preventing further consolidation—especially in pre-training data and model-serving infrastructure—may do more for financial stability than tinkering with capital buffers afterward.
Data commons. Third, use public-good data to tilt the playing field toward challenger models. Central banks have already exchanged supervisory datasets under strict confidentiality. Extending sanitized slices of those datasets to academics and regulated firms—on a share-alike license that requires open-sourcing any derived model—could seed a vibrant ecosystem of specialized, domain-specific AI that captures idiosyncratic risk factors rather than averaging them away. BIS Working Paper 1250, for instance, shows how open stress indicators based on public-market data outperform black-box sentiment scores in predicting liquidity holes precisely because they incorporate diverse modeling assumptions.
Cross-Border Coordination and the Passporting Blueprint
AI risk is borderless, but supervisory authority remains national. London’s AI “sandbox,” launched in June 2025, exemplifies how jurisdictions can foster safe experimentation without stifling innovation. Yet multiple sandboxes equal multiple loopholes: a model rejected by the U.K. Prudential Regulation Authority could still train on an unregulated data lake in a lighter-touch domicile and re-enter via a software-as-a-service contract. A pragmatic fix borrows from the credit-rating-agency rulebook: a passport regime for foundational financial models. Vendors wishing to sell into G-SIBs must pass baseline disclosures—training data provenance, robustness to adversarial inputs, and documented lineage—regardless of domicile. The passport would be time-limited (twelve months) to force continuous transparency about architectural updates.
Federal Reserve Governor Michael Barr’s April 2025 speech gestures in this direction, calling for “orthogonal benchmarking” of supervisory models and acknowledging that alternative modeling channels must balance the central bank’s adoption of vendor LLMs. The speech stops short of a passporting framework but signals that prudential regulators recognize the symmetry problem. If every bank and every watchdog listens to the same oracle, no one notices when the oracle slips.
Safe Intelligence Requires Noisy Markets
Deep learning’s triumph in language and pattern recognition rests on its gift for distillation—compressing oceans of data into probabilistic statements. Yet that gift threatens to erase the noisy pluralism on which market stability has depended since the first stock ticker clattered to life. The empirical trends are clear: rising AI-driven trading volume, growing cross-asset correlations, and SMDRs clustering in the danger zone. None of these guarantees catastrophes, but they shrink the margin for human oversight.
History’s blunt lesson is that crises often incubate in the spaces where incentives align too neatly. In the 2000s, mortgage risk models told thousands of analysts the same comforting story; in the 2010s, clearinghouse netting rewarded everyone for piling into sovereign debt. In the 2020s, the monoculture may be silicon-strung—an invisible lattice of identical embeddings guiding billions of dollars in real-time. Re-injecting diversity—through capital incentives, vendor safeguards, and shared data commons—must rank alongside cyber-resilience and climate transition as a core pillar of macro-prudential policy. The window is closing. Each week, another treasury desk uploads its limit-order books to the same API endpoint. Unless regulators act now to make disagreement an engineering requirement, the next sharp turn in global markets will reveal how little collective wisdom there is when the same machine guides everyone.
The original article was authored by Thierry Foucault, an HEC Foundation Chaired Professor of Finance at HEC Paris School of Management, along with three co-authors. The English version of the article, titled "Artificial intelligence in finance," was published by CEPR on VoxEU.
References
Allied Market Research (2024), Algorithmic Trading Market Size, Share & Forecast 2032 – press release, 18 January.
Bank of England (2025), Financial Policy Committee Record, April 2025.
Coalition Greenwich (2024), “Electronic Platforms Capture Growing Share of U.S. Equity Trading Volume,” press release, 15 December.
Danielsson, J. and Uthemann, A. (2024), “How AI Can Undermine Financial Stability,” CEPR VoxEU Column, 22 January.
Financial Stability Board (2024), The Financial Stability Implications of Artificial Intelligence, 14 November.
International Monetary Fund (2024), Global Financial Stability Report, Chapter 3: “Advances in Artificial Intelligence: Implications for Capital Markets.”
International Monetary Fund (2024), Blog, “Artificial Intelligence Can Make Markets More Efficient—and More Volatile,” 15 October.
Bank for International Settlements (2025), Predicting Financial Market Stress with Machine Learning, BIS Working Paper 1250.
Federal Reserve Board (2025), Speech by Governor Michael S. Barr, “Artificial Intelligence and Banking,” 4 April.




















