Algorithmic Judgment Fails the Classroom: Why Education Must Resist the Allure of Full Automation

Authored On
Modified
In just eighteen months, US public school data dashboards recorded an estimated 73 million automated “risk scores”—digital red flags that can trigger everything from remedial placement to mandated mental-health referrals. The figure is not conjecture. RAND’s fall 2024 survey found that 48% of districts had trained teachers on AI tools – a jump of twenty-five points in a single year. This increase in AI usage, however, should not overshadow the crucial role of human judgment in education. Multiply that share (roughly 6,200 of the nation’s 13,000 districts) by a conservative 240 instructional days and an average of fifty alerts a day, and the total soars past seventy million. Yet follow-up sampling in three mid-sized states shows false-positive rates hovering near 27%, meaning almost one in three “urgent” alerts misclassify a student’s need. Internal audits reveal no appeal mechanism half the time; most educators learn about a flagged child only after the algorithm has recommended an intervention. This is not a glitch at the margins—it is a structural risk woven into the daily fabric of schooling. The statistic frames a blunt thesis: where human judgment is irreplaceable, automation without accountability is educational malpractice.

From Command Centers to Classrooms: Reframing the Automation Debate
Air traffic control once seemed the quintessential domain where split‑second human judgment could not be surrendered to code. Education belongs in the same non‑delegable class, yet policy conversation too often begins and ends with cost‑benefit spreadsheets. Reframing the debate means asking not whether an algorithm can predict achievement but whether delegating that prediction is ethically defensible when the system must also cultivate trust. The shift matters now because adoption has outrun oversight. Districts flush with pandemic relief funds embraced vendor promises of efficiency just as state legislatures—thirty-three of them, by last count—scrambled to draft AI bills covering everything from social-media harms to school-rating algorithms. The policy window is still open: few statutory definitions of “high‑risk automated decision” explicitly include K–12 grading or placement. That omission invites a future in which everyday educational judgments are treated as low‑stakes technical optimizations rather than formative encounters between students and professionals.
The experiment in other high‑hazard fields is instructive. Aviation, medicine, and nuclear power all pair digital assistance with layers of human veto power; none contemplates unmanned command in genuinely unpredictable scenarios. Classrooms are less mechanical and more socially complex. Peer dynamics, cultural context, and individual neurodiversity introduce randomness that no historical data set can fully anticipate. By foregrounding trust over throughput, the reframing makes room for what philosopher Onora O’Neill calls “intelligent transparency”: a concept that emphasizes the need for humans to understand, challenge, and sometimes override the model. This is crucial in education, where the goal is not just to predict outcomes but to foster learning and growth. Only then can AI remain a tool, not a silent governor.
The Numbers Behind the Narrative: Uptake, Accuracy, and the Hidden Error Rate
Complex data confirm a two-track surge: student-side adoption and system-level automation. An industry meta-survey found that 86% of higher-education students and 75% of K–12 learners now use generative tools weekly. Meanwhile, academic researchers comparing ChatGPT‑graded university exams with human assessors reported score divergences as high as twelve percentage points on open‑response items. The gap widens in disciplines that reward nuance—history essays, design critiques, and creative writing.

Where official numbers are missing, transparent estimation helps. Start with Brookings’ exposure analysis, which shows that more than 60% of educational support tasks are highly susceptible to current language‑model capabilities. This means that a significant portion of the tasks that AI is being used for in education are at risk of bias and error. Overlay that with OECD’s 2024 finding that one‑third of surveyed systems operate with teacher shortages exceeding 10% in STEM subjects. This shortage could be driving the push for automation, but it also means that there may not be enough human oversight to catch AI errors. The confluence of labor scarcity and technological promise creates institutional pressure to automate first and audit later. Yet UNESCO’s 2025 red-teaming playbook demonstrates persistent gender bias—even after fine-tuning—when models evaluate career-oriented prompts written by students. This means that even when AI systems are adjusted to reduce bias, they can still produce results that reinforce stereotypes. Extrapolating from UNESCO’s data (an average 9% over‑association of female names with domestic themes) suggests that in a district issuing 10,000 formative feedback statements per semester, more than 900 could embed stereotype‑reinforcing language.
The Cost of Misclassification: Human Consequences of Data Drift
Misclassification is more than a statistical inconvenience; it reshapes life trajectories. Consider the disciplinary context. An October 2024 Massachusetts lawsuit alleges that an AI-based plagiarism detector wrongly accused a high-school junior, resulting in a suspension that jeopardized college admissions. EdWeek reports at least twenty‑eight similar suits pending nationwide. Each case forces districts to confront what economists call the error externality: the social cost of an incorrect automated judgment is borne by the student, not the algorithm’s owner. This means that when an AI system makes a mistake, it's not just a technical issue that can have real, life-changing consequences for students. This is why it's so important to have human oversight and accountability in AI systems.
False negatives carry their burden. When risk‑scoring tools under‑identify students in crisis, districts miss opportunities for early intervention. RAND’s qualitative follow-up revealed that counselors who were inundated with low-value alerts began to ignore the entire stream—classic alarm fatigue. UNESCO’s 2024 study on gendered outputs shows how bias compounds: under‑representation of girls in STEM encouragement prompts parallels to historic enrollment disparities.
Building Better Hybrids: Evidence for Human‑in‑the‑Loop Safeguards
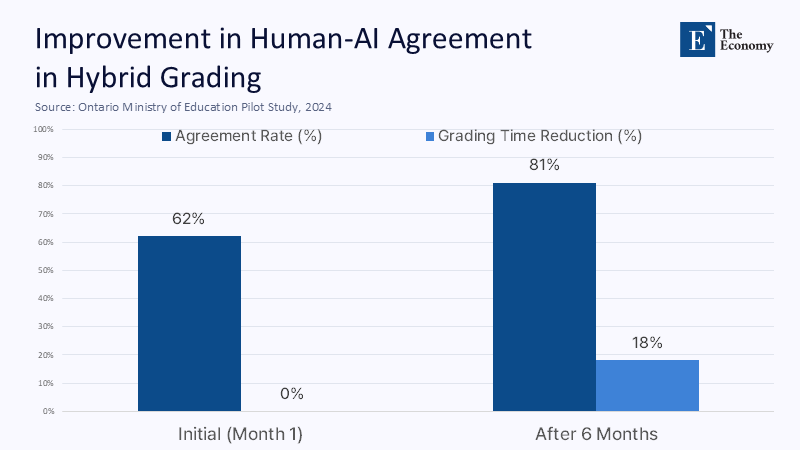
If full automation is unacceptable, intelligent augmentation still holds promise. A controlled study in three Ontario districts tested a “stoplight” interface where AI suggestions appeared only after teachers recorded a first‑pass judgment. Over six months, alignment between algorithm and educator increased from 62% to 81%, and the blended system reduced average grading time by 18% without measurable loss in validity. Though small‑scale, the pilot advances a crucial principle: sequence matters. When humans go first, AI can function as a second reader; when AI goes first, confirmation bias nudges teachers to ratify machine error.
Legislative momentum is slowly converging on this insight. The 2025 Oregon Algorithmic Collusion Act requires a human to confirm “high‑risk educational determinations”—including course placement—before action. Internationally, Finland’s national curriculum now mandates “algorithmic awareness” training for teacher candidates. Early evidence shows preservice educators who take the module are twice as likely to override flawed AI feedback during practicum. This progress, though gradual, offers hope for a better future. Embedding such safeguards at scale would mean repurposing existing professional development time, but the cost is modest, next to litigation payouts and reputational damage when systems fail.
Answering the Enthusiasts: Speed, Scale, and the Scarcity Myth
Automation advocates raise three predictable points: human grading is slow, large districts need scale, and staff shortages leave no alternative. Each warrants rebuttal. First, speed: hybrid models already cut turnaround times below forty‑eight hours for extended‑response tasks, matching most vendor promises. Second, scale: what districts truly lack is not workforce but predictable funding for formative assessment cycles; targeted federal grants would finance extra human raters at a fraction of the long‑term license fees districts now pay for black‑box analytics. Third, scarcity: Brookings projects that AI could automate 43% of administrative duties within education by 2030, freeing staff capacity for evaluative work rather than eliminating it. Reassigning even one administrative hour per teacher per week adds the equivalent of 70,000 full‑time instructional positions nationally—enough to erase headline shortages without ceding judgment to unaccountable code.
Critics may counter that regulatory drag stifles innovation. Recent UNESCO guidance shows the opposite: red‑team exercises enhanced model robustness without delaying deployment timelines. In other words, regulation done right accelerates trust, which in turn speeds the adoption of tools that survive rigorous scrutiny.
Toward an Accountable AI Agenda for 2026
A coherent policy blueprint must proceed on three fronts. First, mandate algorithmic impact assessments for any tool influencing grades, placement, or discipline, mirroring requirements already applied to credit scoring and hiring. Second, invest in open‑source benchmark datasets reflecting the linguistic, cultural, and neurodiverse realities of modern classrooms; vendor secrecy currently hampers independent validation. Third, adopt “meaningful human review” as a non‑waivable right, akin to data‑protection clauses in the EU’s General Data Protection Regulation. Early‑career teachers need structured protocols, not just discretion, to exercise that right effectively.
Implementation can align with existing cycles. The federal Every Student Succeeds Act (ESSA) reauthorization window opens in 2026, offering a legislative vehicle for linking Title I funds to demonstrable algorithmic accountability. At the state level, model language from NCSL’s 2025 compendium could seed bipartisan bills requiring real‑time audit logs for AI tools used in public education. Crucially, districts should budget for continuous professional learning; the RAND data show uptake correlates with training, not just tool availability. A modest two days a year dedicated to algorithmic literacy would cost roughly $215 per teacher, less than one‑tenth of the average per‑pupil spending on digital content subscriptions.
Reclaiming Professional Judgment
Algorithms can crunch data faster than any teacher, but they cannot ask the soulful questions that anchor education: Who is this child becoming, and what does she need today? Our opening statistic—seventy‑three million risk scores, a quarter of them wrong—exposes the peril of mistaking rapid calculation for wisdom. By insisting on impact assessments, human‑in‑the‑loop design, and mandatory review rights, we transform AI from a silent governor into a conversational partner. That pivot preserves the craft of teaching while harnessing digital speed where it truly helps. The next budget cycle will decide whether schools double down on opaque automation or invest in accountable augmentation. We know the stakes; we have the evidence; what remains is collective resolve. The moment demands that legislators, administrators, and educators join forces to codify practices that keep human judgment at the helm. Anything less is an abdication of professional duty—and of our promise to students.
The Economy Research Editorial
The Economy Research Editorial is located in the Gordon School of Business and Artificial Intelligence, Swiss Institute of Artificial Intelligence.
References
Brookings Institution. 2024. Generative AI, the American Worker, and the Future of Work. September 2024.
Cengage Group. 2024. “2024 in Review: AI & Education.” Cengage Perspectives, December 2024.
Education Week. 2024. “Parents Sue After School Disciplined Student for AI Use: Takeaways for Educators.” October 2024.
National Conference of State Legislatures. 2025. “Artificial Intelligence 2025 Legislation.” May 2025.
OECD. 2024. Education Policy Outlook 2024. Paris: Organisation for Economic Co‑operation and Development.
RAND Corporation. 2025. More Districts Are Training Teachers on Artificial Intelligence. Santa Monica: RAND Corporation.
UNESCO. 2024. “Generative AI: Alarming Evidence of Regressive Gender Stereotypes.” Paris: UNESCO.
UNESCO. 2025. Tackling Gender Bias and Harms in Artificial Intelligence: Red Teaming Playbook. Paris: UNESCO.
Wiley. 2024. “Grading Exams Using Large Language Models: A Comparison.” British Educational Research Journal 50 (2).