AI Coding Productivity Is a Coordination Problem: From Writing Code to Shipping Software

Keith Lee is a Professor of AI/Finance at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). His work focuses on AI-driven finance, quantitative modeling, and data-centric approaches to economic and financial systems. He leads research and teaching initiatives that bridge machine learning, financial mathematics, and institutional decision-making.
He also serves as a Senior Research Fellow with the GIAI Council, advising on long-term research direction and global strategy, including SIAI’s academic and institutional initiatives across Europe, Asia, and the Middle East.
Authored On
Modified
AI tools accelerate code generation more than final software delivery Coordination and quality control now limit AI coding productivity Better models will create value only when firms redesign the delivery process

New research on 100,000 developers revealed a striking discrepancy. Since the adoption of three generations of AI programming tools, developers saw a 180% jump in coding activity versus a 30% increase in shipped releases. The exact gains may change as tools improve and measurements become more precise. But the direction is hard to deny. AI can generate code faster than firms can turn it into stable and reliable software. That gap should reset the discussion around AI productivity in coding. The bottleneck isn't typing speed; it is the proficiency with requirements, architecture, review, testing, security, integration, releases and support. A line of code is of very limited use by itself. Software is of limited value until it can operate within the system. Economic value can only be achieved if people recognize its design, trust it, make use of it and then keep using it. AI coding productivity will now depend increasingly less on code generation and more on the complete delivery process.
AI Coding Productivity Is Not Software Productivity
The strongest evidence for AI coding productivity comes from tasks that are closer to the keyboard. In a between-subjects study, programmers using AI coding tools (specifically, GitHub Copilot) finished the same fixed JavaScript task 55.8% faster than users without those tools. Another set of field experiments at Microsoft, Accenture and a large electronics company included 4,867 developers and showed that the availability of an AI coding assistant increased completed tasks by an estimated 26.08%, with bigger effects on less experienced developers. These findings confirm that AI can reduce the drafting cost of functions, syntax recall, test generation and other routine work. These results help explain firms' appetite for adoption. Early-stage industry data now suggest the share of code generated by AI is close to 50% at some firms. Code share is, however, an incomplete indicator of output or value. Certainly, it tells us nothing about how much of the generated code was accepted, revised, removed, mitigated and deployed. Counting code is like counting bricks in a building without taking into account whether the building was built.
Far more revealing evidence emerges from tracking work down the production chain. The large GitHub study compared adopters to hundreds of very similar developers seen one year previously and traced output from commits through to projects and releases. Developers worked on an average 50% more projects but shipped just a 30% increase in releases (or a 42% increase in project-releases), for one generation of the tool. A more than sevenfold increase in lines of code for one generation became only a 65% increase in pull requests and eventually just a 20% increase in releases. App supply also increased, but initial usage of new apps was flat or declining through major marketplaces. This is not to say the productivity gains from AI coding are modest. For example, a 30% increase in releases would be overwhelmingly large across almost any shop floor tool. It is to say that productivity gains become sharply attenuated at each point closer to the final output. Each later stage adds validation, integration, security, product constraints and user needs. The sum of the generated code is not a complete project. The sum of individual projects is not an industrial product. Most of the hard work now takes place in the later stages of that chain.
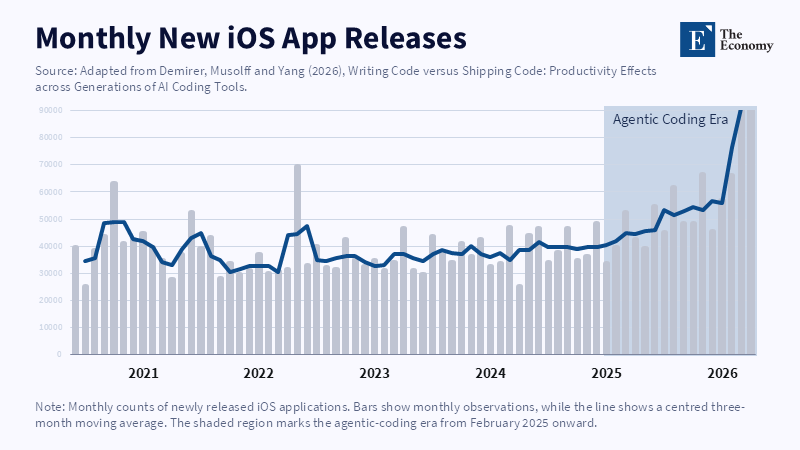
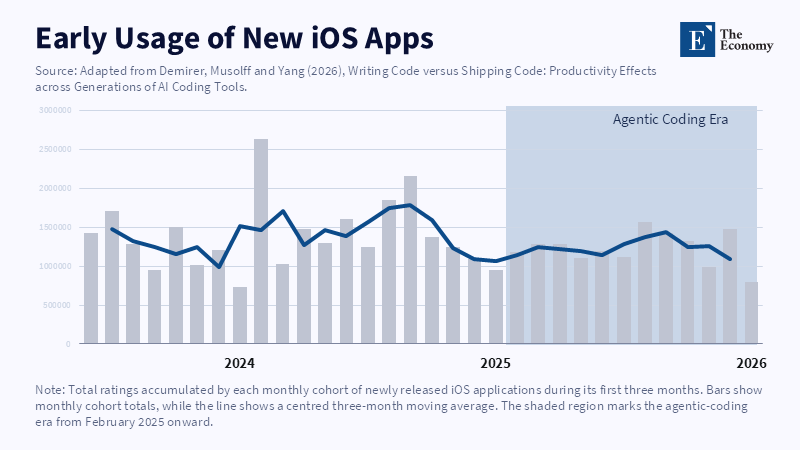
This distinction makes the results of different studies seem contradictory. In early 2025, an RCT recruited 16 seasoned open-source developers to finish 246 real issues inside projects they knew intimately. Developers using AI took 19% longer, despite their subjective sense that their tools had improved productivity. The problems involved mature codebases, implicit conventions and rigorous checking. A subsequent in situ experiment, testing newer tools, detected some speedup, but confidence intervals were wide, sample selection was biased and participants, by and large, did not want to code without AI anymore, but a few avoided tasks that would be painful to finish manually. The take-home is not that the first and second studies were incoherent, but that the circumstances surrounding AI coding affect productivity tremendously: task type, how well a program is done, what machine learning can do fwithin the task, how experienced the developer is and how good the tools are. A short task that passes a test is not the same as a change that survives review and works across a live system.
The Coordination Layer Is Now the Scarce Input
As code becomes less expensive, coordination becomes more fruitful. Every software system contains hidden choices that appear only when looking across the program. A feature may access customer data, billing logic, access structures, legacy interfaces, service quotas and legal responsibilities. AI agents will explore code bases to propose broad changes, but broader changes are also more likely to cause collisions. Many agents may complete local subsystems that collide at the system level, choosing incompatible API patterns, duplicating logic and updating shared components without considering downstream impact. Instead of a traditional bottleneck, this new layer is akin to production planning. It is not government authorization; it is equivalent to firm-level central coordination of work flows, interaction points, quality gates and local optimization to one product vision. Without this layer, rising AI coding efficiency will produce a larger queue rather than more rapid releases.
The 2024 DORA research identified this issue prior to the mass proliferation of the latest agents. For a 25% increase in adoption, there was a 7.5% increase in documentation quality, a 3.4% increase in code quality and a 3.1% increase in speed of reviews; however, this was coupled with a 1.5% decrease in delivery throughput and a 7.2% decrease in delivery stability. These were survey estimates, not causal estimates. Nonetheless, the trend was clear: local excellence did not imply delivery excellence. By 2025, DORA identified a beneficial correlation between adoption and throughput, indicating that teams had figured out how to make the most of the new tools. The negative correlation between adoption and stability persisted, however. The survey covered nearly 5,000 technology professionals worldwide. 90+% used AI at work, 80+% knew it increased productivity, 59% experienced increases in code quality, but simultaneously 30+% had no or limited trust in the quality of AI-produced code. Adoption had gone further than trust.
In the practical world, measure flow, not volume. Leaders should be recording how long changes languish in the review queue, how often they come back again, how many defects escape into production, how quickly a failed release is reinstated and how often people actually use what is shipped. Measures should be broken down where possible between AI-assisted work and non-AI-assisted work. A team that doubles code production while lengthening its review queue has not doubled productivity. A vendor that ships twice as many features and quadruples customer incident rates has not halved the true cost of software. Contracts should move away from hours billed or code delivered. Buyers should be insisting on fewer changes on stable releases, response time, frequency of use, security cost and maintenance expenses. AI may enable a vendor to produce more optimal features in faster cycles at the same or lower cost. That can still be a value, but the improvement should be visible to the customer in some way.
Quality Control Determines Who Captures the Gain
Distribution of gains will depend upon quality control. AI reduces the cost of producing a plausible first answer. It does not eliminate the cost of demonstrating that the answer is safe and appropriate. This is significant because hidden software defects lurk beneath the surface until a rare event reveals them. A report of AI-assisted security tasks observed participants with AI helpers producing less safe code than those working unaided and being prone to a greater belief that the code was safe. The risk was not actually a poor suggestion; it was misplaced confidence. When looking at output that appears polished, review can become less thorough just as the need for review increases. This creates an unseen assurance burden: code that seems complete but has not been sufficiently understood. That debt may not show in sprint metrics until it manifests as outages, security patches, inefficient migrations and slower future changes.
Design reviews require redesigning, not more reviewers. Small changes are still small. Automated tests should test business rules, not only syntax or basic operations. Security scans should happen before code can be presented to a human reviewer. Mission-critical systems should require clear ownership and a record of why a change was made. AI tests should never be accepted as proof for AI code: the same model will always pick up some blind spot in the same way. Review stacks should be risk-based. A routine internal script doesn't need to go through the same process as an identity service, payment system, medical product, or public platform. Governments can help make this transition through procurement. Asking public contractors for evidence about testing, security, incident response, model use and human responsibility is simple and powerful. The goal is not to slow AI coding productivity, but to put human attention where models are least able to replicate human judgement.
The labor effect is similar. Junior programmers will suffer because AI tools are most effective at “bounded, well-defined tasks.” But if companies cut back on junior positions, the future pool of reviewers, architects and technical leads will shrink. Senior judgment is develops through practical experience, through reading existing systems, system debugging and figuring out why a clean-slate change to a legacy system goes nowhere. A company that removes the training ladder in favor of agents may save money now and create skill shortages later. A better approach is to assign routine work to AI tools but in parallel provide junior programmers with training to trace the web of dependency, to prove that a change belongs in a system, to read a specification and test a hypothesis and to evaluate a model’s suggested action or design. Their value should come less from transcribing the reference implementation and more from asserting that a change should be added to an existing system. The key measure should not be the share of code written by a human and by AI, but rather the responsibility for reading and understanding systems and the costs caused by failure.
Cheaper Models Will Move the Bottleneck, Not Remove It
The optimistic scenario is quite compelling. Models are getting better, context windows are getting larger and agents can keep much more project information active during a task. A good memory, retrieval and toolset should lead to increasingly less inconsistent output, as agents can check repositories, run tests, read historic issues and intelligently critique their own output. But this is also a very compelling cost trend. From November 2022 to October 2024, the cost of running a model at around GPT-3.5 performance was reduced from just under $20 per million tokens to just over $0.07 per million tokens, which is a more than 280-fold reduction in costs, on this time horizon. Over the same period, the price performance of AI hardware has improved by 30% per year and the power efficiency of AI hardware by 40% a year. These increases make longer tinference runs, larger context windows, repeated testing and multi-agent workflows seem affordable and again suggest that today’s limits are not fixed, even if the upgraded models to come will still be very costly in terms of compute, storage and control.
However, a bigger context window is not the same as having dependable memory. Research on long-context architectures using modern approaches to training showed performance could diverge when critical details appeared in the middle of a lengthy input. Excess context can introduce additional distractions, dormant rules and contradictory instructions. A product is more than the static code. It is past commitments, promises to users, security expectations, undocumented hacks and associations with external services. More computing can also assist an agent in tracing this material. It cannot determine alone which compromise the enterprise should choose to make; that requires principles, accountability and arithmetic. The main engineering challenge will thus move from code generation to preventing failures and maintaining consistency over time and interacting with other agents. The most valuable improvements from OpenAI, Anthropic and other AI tool developers will come from persistent context, context selection, large-scale testing and coordination, not from generating more code.
The beginning of the gap is the right test. A 180 percent increase in coding activity, along with a 30 percent increase in shipped releases, is not proof that AI has failed, but evidence that producing software is a process of interconnected steps. Faster coding makes downstream delays easier to ignore and can create many more apps than people have time or reason to use. Companies should therefore put as much into delivery mechanisms, testing, platform engineering, product ownership and technical training as they put into models and licenses. Buyers need results they can see instead of eye-catching statistics on code. Policymakers need system accountability. Developers need enduring context, consistent decisions and proof of work. The productivity of coding with AI can become a huge economic boon, but it won't be realized, one task at a time, by substituting programmers. It will be realized by redesigning the organization that turns machine output into software that people can deploy and reliably use.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
Becker, J., Rush, N., Barnes, E. and Rein, D. (2025) ‘Measuring the impact of early-2025 AI on experienced open-source developer productivity’, arXiv preprint arXiv:2507.09089.
Cui, Z.K., Demirer, M., Jaffe, S., Musolff, L., Peng, S. and Salz, T. (2026) ‘The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers’, Management Science, online ahead of print.
Demirer, M., Musolff, L. and Yang, L. (2026a) Writing Code vs. Shipping Code: Productivity Effects across Generations of AI Coding Tools. NBER Working Paper No. 35275. Cambridge, MA: National Bureau of Economic Research.
Demirer, M., Musolff, L. and Yang, L. (2026b) ‘Writing code versus shipping code: Productivity effects across generations of AI coding tools’, VoxEU, 21 June.
Gross, G. (2026) ‘AI is altering the economics of software development, but who gets a cut?’, CIO, 31 March.
Harvey, N. and DeBellis, D. (2024) ‘Highlights from the 10th DORA report’, Google Cloud Blog, 23 October.
Harvey, N. and DeBellis, D. (2025) ‘Announcing the 2025 DORA report: State of AI-assisted software development’, Google Cloud Blog, 23 September.
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F. and Liang, P. (2024) ‘Lost in the middle: How language models use long contexts’, Transactions of the Association for Computational Linguistics, 12, pp. 157–173.
Majic Predin, J. (2026) ‘AI coding agents write 180% more code but ship only 30% more software’, Forbes, 10 June.
Maslej, N., Fattorini, L., Perrault, R., Gil, Y., Parli, V., Kariuki, N., Capstick, E., Reuel, A., Brynjolfsson, E., Etchemendy, J., Ligett, K., Lyons, T., Manyika, J., Niebles, J.C., Shoham, Y., Wald, R., Walsh, T., Hamrah, A., Santarlasci, L., Betts Lotufo, J., Rome, A., Shi, A. and Oak, S. (2025) Artificial Intelligence Index Report 2025. Stanford, CA: Stanford Institute for Human-Centered Artificial Intelligence.
METR (2026) ‘We are changing our developer productivity experiment design’, METR Research Blog.
NextDev AI Team (2026) ‘AI writes 52% of your code. Your economics are wrong’, NextDev, 18 June.
Peng, S., Kalliamvakou, E., Cihon, P. and Demirer, M. (2023) ‘The impact of AI on developer productivity: Evidence from GitHub Copilot’, arXiv preprint arXiv:2302.06590.
Perry, N., Srivastava, M., Kumar, D. and Boneh, D. (2023) ‘Do users write more insecure code with AI assistants?’, in Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. Copenhagen, 26–30 November, pp. 2785–2799.
Keith Lee is a Professor of AI/Finance at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). His work focuses on AI-driven finance, quantitative modeling, and data-centric approaches to economic and financial systems. He leads research and teaching initiatives that bridge machine learning, financial mathematics, and institutional decision-making.
He also serves as a Senior Research Fellow with the GIAI Council, advising on long-term research direction and global strategy, including SIAI’s academic and institutional initiatives across Europe, Asia, and the Middle East.
















